diff --git a/cv/distiller/CWD/pytorch/README.md b/cv/distiller/CWD/pytorch/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..4f02782d0972b2e9239c819efffd68181b1cccbc
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/README.md
@@ -0,0 +1,88 @@
+
+# CWD
+
+> [Channel-wise Knowledge Distillation for Dense Prediction](https://arxiv.org/abs/2011.13256)
+
+
+
+## Abstract
+
+Knowledge distillation (KD) has been proven to be a simple and effective tool for training compact models. Almost all KD variants for dense prediction tasks align the student and teacher networks' feature maps in the spatial domain, typically by minimizing point-wise and/or pair-wise discrepancy. Observing that in semantic segmentation, some layers' feature activations of each channel tend to encode saliency of scene categories (analogue to class activation mapping), we propose to align features channel-wise between the student and teacher networks. To this end, we first transform the feature map of each channel into a probability map using softmax normalization, and then minimize the Kullback-Leibler (KL) divergence of the corresponding channels of the two networks. By doing so, our method focuses on mimicking the soft distributions of channels between networks. In particular, the KL divergence enables learning to pay more attention to the most salient regions of the channel-wise maps, presumably corresponding to the most useful signals for semantic segmentation. Experiments demonstrate that our channel-wise distillation outperforms almost all existing spatial distillation methods for semantic segmentation considerably, and requires less computational cost during training. We consistently achieve superior performance on three benchmarks with various network structures.
+
+## Environment
+
+## install libGL
+yum install mesa-libGL
+
+## install zlib
+wget http://www.zlib.net/fossils/zlib-1.2.9.tar.gz
+tar xvf zlib-1.2.9.tar.gz
+cd zlib-1.2.9/
+./configure && make install
+cd ..
+rm -rf zlib-1.2.9.tar.gz zlib-1.2.9/
+
+
+```
+pip3 install cityscapesscripts addict opencv-python
+cd mmcv
+bash clean_mmcv.sh
+bash build_mmcv.sh
+bash install_mmcv.sh
+cd ../mmrazor
+pip3 install -r requirements.txt
+pip3 install mmcls==v1.0.0rc6
+pip3 install mmsegmentation==v1.0.0
+pip3 install mmengine==0.7.3
+python3 setup.py develop
+```
+
+## Cityscapes
+Cityscapes 官方网站可以下载 [Cityscapes]() 数据集,按照官网要求注册并登陆后,数据可以在[这里]()找到。
+
+```
+mkdir data
+cd data
+# dowmload data
+```
+
+按照惯例,**labelTrainIds.png 用于 cityscapes 训练。 我们提供了一个基于 cityscapesscripts 的脚本用于生成 **labelTrainIds.png。
+```shell
+ ├── data
+ │ ├── cityscapes
+ │ │ ├── leftImg8bit
+ │ │ │ ├── train
+ │ │ │ ├── val
+ │ │ ├── gtFine
+ │ │ │ ├── train
+ │ │ │ ├── val
+ ```
+## --nproc 表示 8 个转换进程,也可以省略。
+```
+cd ..
+python3 tools/dataset_converters/cityscapes.py data/cityscapes --nproc 8
+```
+## Training
+
+### On single GPU
+
+```bash
+python3 tools/train.py configs/distill/mmseg/cwd/cwd_logits_pspnet_r101-d8_pspnet_r18-d8_4xb2-80k_cityscapes-512x1024.py
+```
+
+### Multiple GPUs on one machine
+
+```bash
+bash tools/dist_train.sh configs/distill/mmseg/cwd/cwd_logits_pspnet_r101-d8_pspnet_r18-d8_4xb2-80k_cityscapes-512x1024.py 8
+```
+
+
+
+
+## Segmentation
+
+| model | GPU | FP32 |
+|-------------------| ----------- | ------------------------------------ |
+| pspnet_r18(student) | 8 cards | Miou= 75.32 |
+
+
diff --git a/cv/distiller/CWD/pytorch/mmcv/.dockerignore b/cv/distiller/CWD/pytorch/mmcv/.dockerignore
new file mode 100644
index 0000000000000000000000000000000000000000..8c22f226d3e2d8a625515290691d2cfc6ed87f2e
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/.dockerignore
@@ -0,0 +1,6 @@
+.git
+.gitignore
+*.egg-info
+.eggs/
+.mypy-cache
+pip-wheel-metadata
diff --git a/cv/distiller/CWD/pytorch/mmcv/.pre-commit-config.yaml b/cv/distiller/CWD/pytorch/mmcv/.pre-commit-config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..19e9f8d4813d7dafc5d7659b0e95cca161b966ff
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/.pre-commit-config.yaml
@@ -0,0 +1,54 @@
+exclude: ^tests/data/
+repos:
+ - repo: https://gitlab.com/pycqa/flake8.git
+ rev: 3.8.3
+ hooks:
+ - id: flake8
+ - repo: https://github.com/asottile/seed-isort-config
+ rev: v2.2.0
+ hooks:
+ - id: seed-isort-config
+ - repo: https://github.com/timothycrosley/isort
+ rev: 4.3.21
+ hooks:
+ - id: isort
+ - repo: https://github.com/pre-commit/mirrors-yapf
+ rev: v0.30.0
+ hooks:
+ - id: yapf
+ - repo: https://github.com/pre-commit/pre-commit-hooks
+ rev: v3.1.0
+ hooks:
+ - id: trailing-whitespace
+ - id: check-yaml
+ - id: end-of-file-fixer
+ - id: requirements-txt-fixer
+ - id: double-quote-string-fixer
+ - id: check-merge-conflict
+ - id: fix-encoding-pragma
+ args: ["--remove"]
+ - id: mixed-line-ending
+ args: ["--fix=lf"]
+ - repo: https://github.com/jumanjihouse/pre-commit-hooks
+ rev: 2.1.4
+ hooks:
+ - id: markdownlint
+ args: ["-r", "~MD002,~MD013,~MD029,~MD033,~MD034",
+ "-t", "allow_different_nesting"]
+ - repo: https://github.com/codespell-project/codespell
+ rev: v2.1.0
+ hooks:
+ - id: codespell
+ - repo: https://github.com/myint/docformatter
+ rev: v1.3.1
+ hooks:
+ - id: docformatter
+ args: ["--in-place", "--wrap-descriptions", "79"]
+ # - repo: local
+ # hooks:
+ # - id: clang-format
+ # name: clang-format
+ # description: Format files with ClangFormat
+ # entry: clang-format -style=google -i
+ # language: system
+ # files: \.(c|cc|cxx|cpp|cu|h|hpp|hxx|cuh|proto)$
diff --git a/cv/distiller/CWD/pytorch/mmcv/.readthedocs.yml b/cv/distiller/CWD/pytorch/mmcv/.readthedocs.yml
new file mode 100644
index 0000000000000000000000000000000000000000..7d5f1c2060a64e5cf9c2bec433cd24532a283164
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/.readthedocs.yml
@@ -0,0 +1,9 @@
+version: 2
+
+formats: all
+
+python:
+ version: 3.7
+ install:
+ - requirements: requirements/runtime.txt
+ - requirements: requirements/docs.txt
diff --git a/cv/distiller/CWD/pytorch/mmcv/CITATION.cff b/cv/distiller/CWD/pytorch/mmcv/CITATION.cff
new file mode 100644
index 0000000000000000000000000000000000000000..786117aac3e063efc18ad1b55e163d570a09e379
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/CITATION.cff
@@ -0,0 +1,8 @@
+cff-version: 1.2.0
+message: "If you use this software, please cite it as below."
+authors:
+ - name: "MMCV Contributors"
+title: "OpenMMLab Computer Vision Foundation"
+date-released: 2018-08-22
+url: "https://github.com/open-mmlab/mmcv"
+license: Apache-2.0
diff --git a/cv/distiller/CWD/pytorch/mmcv/CONTRIBUTING.md b/cv/distiller/CWD/pytorch/mmcv/CONTRIBUTING.md
new file mode 100644
index 0000000000000000000000000000000000000000..184a6bd2c6dacbba0866a91ca0226854b8d06f01
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/CONTRIBUTING.md
@@ -0,0 +1,258 @@
+## Contributing to OpenMMLab
+
+Welcome to the MMCV community, we are committed to building a cutting-edge computer vision foundational library and all kinds of contributions are welcomed, including but not limited to
+
+**Fix bug**
+
+You can directly post a Pull Request to fix typo in code or documents
+
+The steps to fix the bug of code implementation are as follows.
+
+1. If the modification involve significant changes, you should create an issue first and describe the error information and how to trigger the bug. Other developers will discuss with you and propose an proper solution.
+
+2. Posting a pull request after fixing the bug and adding corresponding unit test.
+
+**New Feature or Enhancement**
+
+1. If the modification involve significant changes, you should create an issue to discuss with our developers to propose an proper design.
+2. Post a Pull Request after implementing the new feature or enhancement and add corresponding unit test.
+
+**Document**
+
+You can directly post a pull request to fix documents. If you want to add a document, you should first create an issue to check if it is reasonable.
+
+### Pull Request Workflow
+
+If you're not familiar with Pull Request, don't worry! The following guidance will tell you how to create a Pull Request step by step. If you want to dive into the develop mode of Pull Request, you can refer to the [official documents](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+#### 1. Fork and clone
+
+If you are posting a pull request for the first time, you should fork the OpenMMLab repositories by clicking the **Fork** button in the top right corner of the GitHub page, and the forked repositories will appear under your GitHub profile.
+
+
+
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/mmcv.git
+```
+
+After that, you should ddd official repository as the upstream repository
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmcv
+```
+
+Check whether remote repository has been added successfully by `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmcv.git (fetch)
+origin git@github.com:{username}/mmcv.git (push)
+upstream git@github.com:open-mmlab/mmcv (fetch)
+upstream git@github.com:open-mmlab/mmcv (push)
+```
+
+> Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+
+#### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of OpenMMLab. **Note**: The following code should be executed under the MMCV directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+
+
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+
+
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**).
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream master
+```
+
+#### 4. Commit the code and pass the unit test
+
+- MMCV introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of runner
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+#### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
+
+#### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+
+
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
+
+
+
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)
+
+(b) If it is your first contribution, please sign the CLA
+
+
+
+(c) Check whether the Pull Request pass through the CI
+
+
+
+MMCV will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+
+
+#### 7. Resolve conflicts
+
+If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
+
+### Guidance
+
+#### Unit test
+
+If you cannot run the unit test of some modules for lacking of some dependencies, such as [video](https://github.com/open-mmlab/mmcv/tree/master/mmcv/video) module, you can try to install the following dependencies:
+
+```shell
+# Linux
+sudo apt-get update -y
+sudo apt-get install -y libturbojpeg
+sudo apt-get install -y ffmpeg
+
+# Windows
+conda install ffmpeg
+```
+
+We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Code style
+
+#### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](./setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `float-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](./.pre-commit-config.yaml).
+
+#### C++ and CUDA
+
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
+
+### PR Specs
+
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
+
+2. One short-time branch should be matched with only one PR
+
+3. Accomplish a detailed change in one PR. Avoid large PR
+
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
+
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/cv/distiller/CWD/pytorch/mmcv/CONTRIBUTING_zh-CN.md b/cv/distiller/CWD/pytorch/mmcv/CONTRIBUTING_zh-CN.md
new file mode 100644
index 0000000000000000000000000000000000000000..52cc1ab5b2d399557647604018c494e4f93a1d24
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/CONTRIBUTING_zh-CN.md
@@ -0,0 +1,274 @@
+## 贡献代码
+
+欢迎加入 MMCV 社区,我们致力于打造最前沿的计算机视觉基础库,我们欢迎任何类型的贡献,包括但不限于
+
+**修复错误**
+
+修复代码实现错误的步骤如下:
+
+1. 如果提交的代码改动较大,建议先提交 issue,并正确描述 issue 的现象、原因和复现方式,讨论后确认修复方案。
+2. 修复错误并补充相应的单元测试,提交拉取请求。
+
+**新增功能或组件**
+
+1. 如果新功能或模块涉及较大的代码改动,建议先提交 issue,确认功能的必要性。
+2. 实现新增功能并添单元测试,提交拉取请求。
+
+**文档补充**
+
+修复文档可以直接提交拉取请求
+
+添加文档或将文档翻译成其他语言步骤如下
+
+1. 提交 issue,确认添加文档的必要性。
+2. 添加文档,提交拉取请求。
+
+### 拉取请求工作流
+
+如果你对拉取请求不了解,没关系,接下来的内容将会从零开始,一步一步地指引你如何创建一个拉取请求。如果你想深入了解拉取请求的开发模式,可以参考 github [官方文档](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+#### 1. 复刻仓库
+
+当你第一次提交拉取请求时,先复刻 OpenMMLab 原代码库,点击 GitHub 页面右上角的 **Fork** 按钮,复刻后的代码库将会出现在你的 GitHub 个人主页下。
+
+
+
+将代码克隆到本地
+
+```shell
+git clone git@github.com:{username}/mmcv.git
+```
+
+添加原代码库为上游代码库
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmcv
+```
+
+检查 remote 是否添加成功,在终端输入 `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmcv.git (fetch)
+origin git@github.com:{username}/mmcv.git (push)
+upstream git@github.com:open-mmlab/mmcv (fetch)
+upstream git@github.com:open-mmlab/mmcv (push)
+```
+
+> 这里对 origin 和 upstream 进行一个简单的介绍,当我们使用 git clone 来克隆代码时,会默认创建一个 origin 的 remote,它指向我们克隆的代码库地址,而 upstream 则是我们自己添加的,用来指向原始代码库地址。当然如果你不喜欢他叫 upstream,也可以自己修改,比如叫 open-mmlab。我们通常向 origin 提交代码(即 fork 下来的远程仓库),然后向 upstream 提交一个 pull request。如果提交的代码和最新的代码发生冲突,再从 upstream 拉取最新的代码,和本地分支解决冲突,再提交到 origin。
+
+#### 2. 配置 pre-commit
+
+在本地开发环境中,我们使用 [pre-commit](https://pre-commit.com/#intro) 来检查代码风格,以确保代码风格的统一。在提交代码,需要先安装 pre-commit(需要在 MMCV 目录下执行):
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+检查 pre-commit 是否配置成功,并安装 `.pre-commit-config.yaml` 中的钩子:
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+
+
+> 如果你是中国用户,由于网络原因,可能会出现安装失败的情况,这时可以使用国内源
+
+> pre-commit install -c .pre-commit-config-zh-cn.yaml
+
+> pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+
+如果安装过程被中断,可以重复执行 `pre-commit run ...` 继续安装。
+
+如果提交的代码不符合代码风格规范,pre-commit 会发出警告,并自动修复部分错误。
+
+
+
+如果我们想临时绕开 pre-commit 的检查提交一次代码,可以在 `git commit` 时加上 `--no-verify`(需要保证最后推送至远程仓库的代码能够通过 pre-commit 检查)。
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. 创建开发分支
+
+安装完 pre-commit 之后,我们需要基于 master 创建开发分支,建议的分支命名规则为 `username/pr_name`。
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+在后续的开发中,如果本地仓库的 master 分支落后于 upstream 的 master 分支,我们需要先拉取 upstream 的代码进行同步,再执行上面的命令
+
+```shell
+git pull upstream master
+```
+
+#### 4. 提交代码并在本地通过单元测试
+
+- MMCV 引入了 mypy 来做静态类型检查,以增加代码的鲁棒性。因此我们在提交代码时,需要补充 Type Hints。具体规则可以参考[教程](https://zhuanlan.zhihu.com/p/519335398)。
+
+- 提交的代码同样需要通过单元测试
+
+ ```shell
+ # 通过全量单元测试
+ pytest tests
+
+ # 我们需要保证提交的代码能够通过修改模块的单元测试,以 runner 为例
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ 如果你由于缺少依赖无法运行修改模块的单元测试,可以参考[指引-单元测试](#单元测试)
+
+- 如果修改/添加了文档,参考[指引](#文档渲染)确认文档渲染正常。
+
+#### 5. 推送代码到远程
+
+代码通过单元测试和 pre-commit 检查后,将代码推送到远程仓库,如果是第一次推送,可以在 `git push` 后加上 `-u` 参数以关联远程分支
+
+```shell
+git push -u origin {branch_name}
+```
+
+这样下次就可以直接使用 `git push` 命令推送代码了,而无需指定分支和远程仓库。
+
+#### 6. 提交拉取请求(PR)
+
+(1) 在 GitHub 的 Pull request 界面创建拉取请求
+
+
+(2) 根据指引修改 PR 描述,以便于其他开发者更好地理解你的修改
+
+
+
+描述规范详见[拉取请求规范](#拉取请求规范)
+
+
+
+**注意事项**
+
+(a) PR 描述应该包含修改理由、修改内容以及修改后带来的影响,并关联相关 Issue(具体方式见[文档](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) 如果是第一次为 OpenMMLab 做贡献,需要签署 CLA
+
+
+
+(c) 检查提交的 PR 是否通过 CI(集成测试)
+
+
+
+MMCV 会在不同的平台(Linux、Window、Mac),基于不同版本的 Python、PyTorch、CUDA 对提交的代码进行单元测试,以保证代码的正确性,如果有任何一个没有通过,我们可点击上图中的 `Details` 来查看具体的测试信息,以便于我们修改代码。
+
+(3) 如果 PR 通过了 CI,那么就可以等待其他开发者的 review,并根据 reviewer 的意见,修改代码,并重复 [4](#4-提交代码并本地通过单元测试)-[5](#5-推送代码到远程) 步骤,直到 reviewer 同意合入 PR。
+
+
+
+所有 reviewer 同意合入 PR 后,我们会尽快将 PR 合并到主分支。
+
+#### 7. 解决冲突
+
+随着时间的推移,我们的代码库会不断更新,这时候,如果你的 PR 与主分支存在冲突,你需要解决冲突,解决冲突的方式有两种:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+或者
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+如果你非常善于处理冲突,那么可以使用 rebase 的方式来解决冲突,因为这能够保证你的 commit log 的整洁。如果你不太熟悉 `rebase` 的使用,那么可以使用 `merge` 的方式来解决冲突。
+
+### 指引
+
+#### 单元测试
+
+如果你无法正常执行部分模块的单元测试,例如 [video](https://github.com/open-mmlab/mmcv/tree/master/mmcv/video) 模块,可能是你的当前环境没有安装以下依赖
+
+```shell
+# Linux
+sudo apt-get update -y
+sudo apt-get install -y libturbojpeg
+sudo apt-get install -y ffmpeg
+
+# Windows
+conda install ffmpeg
+```
+
+在提交修复代码错误或新增特性的拉取请求时,我们应该尽可能的让单元测试覆盖所有提交的代码,计算单元测试覆盖率的方法如下
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### 文档渲染
+
+在提交修复代码错误或新增特性的拉取请求时,可能会需要修改/新增模块的 docstring。我们需要确认渲染后的文档样式是正确的。
+本地生成渲染后的文档的方法如下
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### 代码风格
+
+#### Python
+
+[PEP8](https://www.python.org/dev/peps/pep-0008/) 作为 OpenMMLab 算法库首选的代码规范,我们使用以下工具检查和格式化代码
+
+- [flake8](https://github.com/PyCQA/flake8): Python 官方发布的代码规范检查工具,是多个检查工具的封装
+- [isort](https://github.com/timothycrosley/isort): 自动调整模块导入顺序的工具
+- [yapf](https://github.com/google/yapf): Google 发布的代码规范检查工具
+- [codespell](https://github.com/codespell-project/codespell): 检查单词拼写是否有误
+- [mdformat](https://github.com/executablebooks/mdformat): 检查 markdown 文件的工具
+- [docformatter](https://github.com/myint/docformatter): 格式化 docstring 的工具
+
+yapf 和 isort 的配置可以在 [setup.cfg](./setup.cfg) 找到
+
+通过配置 [pre-commit hook](https://pre-commit.com/) ,我们可以在提交代码时自动检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`、`markdown files`,
+修复 `end-of-files`、`float-quoted-strings`、`python-encoding-pragma`、`mixed-line-ending`,调整 `requirments.txt` 的包顺序。
+pre-commit 钩子的配置可以在 [.pre-commit-config](./.pre-commit-config.yaml) 找到。
+
+pre-commit 具体的安装使用方式见[拉取请求](#2-配置-pre-commit)。
+
+更具体的规范请参考 [OpenMMLab 代码规范](code_style.md)。
+
+#### C++ and CUDA
+
+C++ 和 CUDA 的代码规范遵从 [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html)
+
+### 拉取请求规范
+
+1. 使用 [pre-commit hook](https://pre-commit.com),尽量减少代码风格相关问题
+
+2. 一个`拉取请求`对应一个短期分支
+
+3. 粒度要细,一个`拉取请求`只做一件事情,避免超大的`拉取请求`
+
+ - Bad:实现 Faster R-CNN
+ - Acceptable:给 Faster R-CNN 添加一个 box head
+ - Good:给 box head 增加一个参数来支持自定义的 conv 层数
+
+4. 每次 Commit 时需要提供清晰且有意义 commit 信息
+
+5. 提供清晰且有意义的`拉取请求`描述
+
+ - 标题写明白任务名称,一般格式:\[Prefix\] Short description of the pull request (Suffix)
+ - prefix: 新增功能 \[Feature\], 修 bug \[Fix\], 文档相关 \[Docs\], 开发中 \[WIP\] (暂时不会被review)
+ - 描述里介绍`拉取请求`的主要修改内容,结果,以及对其他部分的影响, 参考`拉取请求`模板
+ - 关联相关的`议题` (issue) 和其他`拉取请求`
+
+6. 如果引入了其他三方库,或借鉴了三方库的代码,请确认他们的许可证和 mmcv 兼容,并在借鉴的代码上补充 `This code is inspired from http://`
diff --git a/cv/distiller/CWD/pytorch/mmcv/Jenkinsfile b/cv/distiller/CWD/pytorch/mmcv/Jenkinsfile
new file mode 100644
index 0000000000000000000000000000000000000000..f0c19d9f3c3e0efc9ed218efa2259c598e383a06
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/Jenkinsfile
@@ -0,0 +1,56 @@
+def docker_images = ["registry.cn-hangzhou.aliyuncs.com/sensetime/openmmlab:cuda10.1-cudnn7-devel-ubuntu18.04-py37-pt1.3",
+ "registry.cn-hangzhou.aliyuncs.com/sensetime/openmmlab:cuda10.2-cudnn7-devel-ubuntu18.04-py37-pt1.5"]
+def torch_versions = ["1.3.0", "1.5.0"]
+def torchvision_versions = ["0.4.2", "0.6.0"]
+
+
+def get_stages(docker_image, folder) {
+ def pip_mirror = "-i https://mirrors.aliyun.com/pypi/simple"
+ stages = {
+ docker.image(docker_image).inside('-u root --gpus all --net host') {
+ sh "rm -rf ${env.WORKSPACE}-${folder} ${env.WORKSPACE}-${folder}@tmp"
+ sh "cp -r ${env.WORKSPACE} ${env.WORKSPACE}-${folder}"
+ try {
+ dir("${env.WORKSPACE}-${folder}") {
+ stage("before_install") {
+ sh "apt-get update && apt-get install -y ninja-build"
+ }
+ stage("dependencies") {
+ // torch and torchvision are pre-installed in dockers
+ sh "pip list | grep torch"
+ sh "apt-get install -y ffmpeg libturbojpeg"
+ sh "pip install pytest coverage lmdb PyTurboJPEG Cython ${pip_mirror}"
+ }
+ stage("build") {
+ sh "MMCV_WITH_OPS=1 pip install -e . ${pip_mirror}"
+ }
+ stage("test") {
+ sh "coverage run --branch --source=mmcv -m pytest tests/"
+ sh "coverage xml"
+ sh "coverage report -m"
+ }
+ }
+ } finally {
+ sh "rm -rf ${env.WORKSPACE}-${folder} ${env.WORKSPACE}-${folder}@tmp"
+ }
+ }
+ }
+ return stages
+}
+
+
+node('master') {
+ // fetch latest change from SCM (Source Control Management)
+ checkout scm
+
+ def stages = [:]
+ for (int i = 0; i < docker_images.size(); i++) {
+ def docker_image = docker_images[i]
+ def torch = torch_versions[i]
+ def torchvision = torchvision_versions[i]
+ def tag = docker_image + '_' + torch + '_' + torchvision
+ def folder = "${i}"
+ stages[tag] = get_stages(docker_image, folder)
+ }
+ parallel stages
+}
diff --git a/cv/distiller/CWD/pytorch/mmcv/LICENSE b/cv/distiller/CWD/pytorch/mmcv/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..f02314255d824c0816b0bf1648aac8ab78976199
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/LICENSE
@@ -0,0 +1,203 @@
+Copyright (c) OpenMMLab. All rights reserved
+
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright 2018-2020 Open-MMLab. All rights reserved.
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/cv/distiller/CWD/pytorch/mmcv/LICENSES.md b/cv/distiller/CWD/pytorch/mmcv/LICENSES.md
new file mode 100644
index 0000000000000000000000000000000000000000..5de8358331f4d21529e016807b86b66dc6ca29da
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/LICENSES.md
@@ -0,0 +1,8 @@
+# Licenses for special operations
+
+In this file, we list the operations with other licenses instead of Apache 2.0. Users should be careful about adopting these operations in any commercial matters.
+
+| Operation | Files | License |
+| :--------------: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------: | :------------: |
+| upfirdn2d | [mmcv/ops/csrc/pytorch/cuda/upfirdn2d_kernel.cu](https://github.com/open-mmlab/mmcv/blob/master/mmcv/ops/csrc/pytorch/cuda/upfirdn2d_kernel.cu) | NVIDIA License |
+| fused_leaky_relu | [mmcv/ops/csrc/pytorch/cuda/fused_bias_leakyrelu_cuda.cu](https://github.com/open-mmlab/mmcv/blob/master/mmcv/ops/csrc/pytorch/cuda/fused_bias_leakyrelu_cuda.cu) | NVIDIA License |
diff --git a/cv/distiller/CWD/pytorch/mmcv/MANIFEST.in b/cv/distiller/CWD/pytorch/mmcv/MANIFEST.in
new file mode 100644
index 0000000000000000000000000000000000000000..622635caa1ec01f78d95c684b87658df87c63b38
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/MANIFEST.in
@@ -0,0 +1,6 @@
+include requirements/runtime.txt
+include mmcv/ops/csrc/common/cuda/*.cuh mmcv/ops/csrc/common/cuda/*.hpp mmcv/ops/csrc/common/*.hpp
+include mmcv/ops/csrc/pytorch/*.cpp mmcv/ops/csrc/pytorch/cuda/*.cu mmcv/ops/csrc/pytorch/cuda/*.cpp mmcv/ops/csrc/pytorch/cpu/*.cpp
+include mmcv/ops/csrc/parrots/*.h mmcv/ops/csrc/parrots/*.cpp
+include mmcv/ops/csrc/pytorch/mps/*.mm mmcv/ops/csrc/common/mps/*.h mmcv/ops/csrc/common/mps/*.mm
+recursive-include mmcv/ops/csrc/ *.h *.hpp *.cpp *.cuh *.cu *.mm
diff --git a/cv/distiller/CWD/pytorch/mmcv/README.md b/cv/distiller/CWD/pytorch/mmcv/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..25d290f3dac27c8f0e87b0256ed8b0964d5bbcc9
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/README.md
@@ -0,0 +1,161 @@
+
+
+[](https://mmcv.readthedocs.io/en/2.x/)
+[](https://mmcv.readthedocs.io/en/2.x/get_started/installation.html)
+[](https://pypi.org/project/mmcv/)
+[](https://pytorch.org/get-started/previous-versions/)
+[](https://developer.nvidia.com/cuda-downloads)
+[](https://pypi.org/project/mmcv)
+[](https://github.com/open-mmlab/mmcv/actions)
+[](https://codecov.io/gh/open-mmlab/mmcv)
+[](https://github.com/open-mmlab/mmcv/blob/master/LICENSE)
+
+English | [简体中文](README_zh-CN.md)
+
+## Introduction
+
+MMCV is a foundational library for computer vision research and it provides the following functionalities:
+
+- [Image/Video processing](https://mmcv.readthedocs.io/en/2.x/understand_mmcv/data_process.html)
+- [Image and annotation visualization](https://mmcv.readthedocs.io/en/2.x/understand_mmcv/visualization.html)
+- [Image transformation](https://mmcv.readthedocs.io/en/2.x/understand_mmcv/data_transform.html)
+- [Various CNN architectures](https://mmcv.readthedocs.io/en/2.x/understand_mmcv/cnn.html)
+- [High-quality implementation of common CPU and CUDA ops](https://mmcv.readthedocs.io/en/2.x/understand_mmcv/ops.html)
+
+It supports the following systems:
+
+- Linux
+- Windows
+- macOS
+
+See the [documentation](http://mmcv.readthedocs.io/en/2.x) for more features and usage.
+
+Note: MMCV requires Python 3.7+.
+
+## Installation
+
+There are two versions of MMCV:
+
+- **mmcv**: comprehensive, with full features and various CUDA ops out of the box. It takes longer time to build.
+- **mmcv-lite**: lite, without CUDA ops but all other features, similar to mmcv\<1.0.0. It is useful when you do not need those CUDA ops.
+
+**Note**: Do not install both versions in the same environment, otherwise you may encounter errors like `ModuleNotFound`. You need to uninstall one before installing the other. `Installing the full version is highly recommended if CUDA is available`.
+
+### Install mmcv
+
+Before installing mmcv, make sure that PyTorch has been successfully installed following the [PyTorch official installation guide](https://github.com/pytorch/pytorch#installation). For apple silicon users, please use PyTorch 1.13+.
+
+The command to install mmcv:
+
+```bash
+pip install -U openmim
+mim install "mmcv>=2.0.0rc1"
+```
+
+If you need to specify the version of mmcv, you can use the following command:
+
+```bash
+mim install mmcv==2.0.0rc3
+```
+
+If you find that the above installation command does not use a pre-built package ending with `.whl` but a source package ending with `.tar.gz`, you may not have a pre-build package corresponding to the PyTorch or CUDA or mmcv version, in which case you can [build mmcv from source](https://mmcv.readthedocs.io/en/2.x/get_started/build.html).
+
+
+Installation log using pre-built packages
+
+Looking in links: https://download.openmmlab.com/mmcv/dist/cu102/torch1.8.0/index.html
+Collecting mmcv
+Downloading https://download.openmmlab.com/mmcv/dist/cu102/torch1.8.0/mmcv-2.0.0rc3-cp38-cp38-manylinux1_x86_64.whl
+
+
+
+
+Installation log using source packages
+
+Looking in links: https://download.openmmlab.com/mmcv/dist/cu102/torch1.8.0/index.html
+Collecting mmcv==2.0.0rc3
+Downloading mmcv-2.0.0rc3.tar.gz
+
+
+
+For more installation methods, please refer to the [Installation documentation](https://mmcv.readthedocs.io/en/2.x/get_started/installation.html).
+
+### Install mmcv-lite
+
+If you need to use PyTorch-related modules, make sure PyTorch has been successfully installed in your environment by referring to the [PyTorch official installation guide](https://github.com/pytorch/pytorch#installation).
+
+```bash
+pip install -U openmim
+mim install "mmcv-lite>=2.0.0rc1"
+```
+
+## FAQ
+
+If you face some installation issues, CUDA related issues or RuntimeErrors,
+you may first refer to this [Frequently Asked Questions](https://mmcv.readthedocs.io/en/2.x/faq.html).
+
+If you face installation problems or runtime issues, you may first refer to this [Frequently Asked Questions](https://mmcv.readthedocs.io/en/2.x/faq.html) to see if there is a solution. If the problem is still not solved, feel free to open an [issue](https://github.com/open-mmlab/mmcv/issues).
+
+## Citation
+
+If you find this project useful in your research, please consider cite:
+
+```latex
+@misc{mmcv,
+ title={{MMCV: OpenMMLab} Computer Vision Foundation},
+ author={MMCV Contributors},
+ howpublished = {\url{https://github.com/open-mmlab/mmcv}},
+ year={2018}
+}
+```
+
+## Contributing
+
+We appreciate all contributions to improve MMCV. Please refer to [CONTRIBUTING.md](CONTRIBUTING.md) for the contributing guideline.
+
+## License
+
+MMCV is released under the Apache 2.0 license, while some specific operations in this library are with other licenses. Please refer to [LICENSES.md](LICENSES.md) for the careful check, if you are using our code for commercial matters.
+
+## Projects in OpenMMLab
+
+- [MMEngine](https://github.com/open-mmlab/mmengine): OpenMMLab foundational library for training deep learning models.
+- [MMCV](https://github.com/open-mmlab/mmcv): OpenMMLab foundational library for computer vision.
+- [MIM](https://github.com/open-mmlab/mim): MIM installs OpenMMLab packages.
+- [MMClassification](https://github.com/open-mmlab/mmclassification): OpenMMLab image classification toolbox and benchmark.
+- [MMDetection](https://github.com/open-mmlab/mmdetection): OpenMMLab detection toolbox and benchmark.
+- [MMDetection3D](https://github.com/open-mmlab/mmdetection3d): OpenMMLab's next-generation platform for general 3D object detection.
+- [MMRotate](https://github.com/open-mmlab/mmrotate): OpenMMLab rotated object detection toolbox and benchmark.
+- [MMYOLO](https://github.com/open-mmlab/mmyolo): OpenMMLab YOLO series toolbox and benchmark.
+- [MMSegmentation](https://github.com/open-mmlab/mmsegmentation): OpenMMLab semantic segmentation toolbox and benchmark.
+- [MMOCR](https://github.com/open-mmlab/mmocr): OpenMMLab text detection, recognition, and understanding toolbox.
+- [MMPose](https://github.com/open-mmlab/mmpose): OpenMMLab pose estimation toolbox and benchmark.
+- [MMHuman3D](https://github.com/open-mmlab/mmhuman3d): OpenMMLab 3D human parametric model toolbox and benchmark.
+- [MMSelfSup](https://github.com/open-mmlab/mmselfsup): OpenMMLab self-supervised learning toolbox and benchmark.
+- [MMRazor](https://github.com/open-mmlab/mmrazor): OpenMMLab model compression toolbox and benchmark.
+- [MMFewShot](https://github.com/open-mmlab/mmfewshot): OpenMMLab fewshot learning toolbox and benchmark.
+- [MMAction2](https://github.com/open-mmlab/mmaction2): OpenMMLab's next-generation action understanding toolbox and benchmark.
+- [MMTracking](https://github.com/open-mmlab/mmtracking): OpenMMLab video perception toolbox and benchmark.
+- [MMFlow](https://github.com/open-mmlab/mmflow): OpenMMLab optical flow toolbox and benchmark.
+- [MMEditing](https://github.com/open-mmlab/mmediting): OpenMMLab image and video editing toolbox.
+- [MMGeneration](https://github.com/open-mmlab/mmgeneration): OpenMMLab image and video generative models toolbox.
+- [MMDeploy](https://github.com/open-mmlab/mmdeploy): OpenMMLab model deployment framework.
diff --git a/cv/distiller/CWD/pytorch/mmcv/README_zh-CN.md b/cv/distiller/CWD/pytorch/mmcv/README_zh-CN.md
new file mode 100644
index 0000000000000000000000000000000000000000..d9a81ebf58c7e5578e7b43d9803cd9a2b69bdd9b
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/README_zh-CN.md
@@ -0,0 +1,164 @@
+
Input features. 4-D tensor of shape (N, C, H, W). N is the batch size.
+
masks: T
+
The input mask
+
+
+### Outputs
+
+
+
output: T
+
The upsampled features. 4-D tensor of shape (N, C, H * scale_factor, W * scale_factor). N is the batch size.
+
+
+### Type Constraints
+
+- T:tensor(float32)
+
+## MMCVCAWeight
+
+### Description
+
+Operator for Criss-Cross Attention
+Read [CCNet: Criss-Cross Attention for SemanticSegmentation](https://arxiv.org/pdf/1811.11721.pdf) for more detailed information.
+
+### Parameters
+
+None
+
+### Inputs
+
+
+
t: T
+
The query matrix of shape (N, C', H, W).
+
f: T
+
The key matrix of shape (N, C', H, W).
+
+
+### Outputs
+
+
+
weight: T
+
The attention map of shape (N, H+W-1, H, W).
+
+
+### Type Constraints
+
+- T:tensor(float32)
+
+## MMCVCAMap
+
+### Description
+
+Operator for Criss-Cross Attention
+Read [CCNet: Criss-Cross Attention for SemanticSegmentation](https://arxiv.org/pdf/1811.11721.pdf) for more detailed information.
+
+### Parameters
+
+None
+
+### Inputs
+
+
+
weight: T
+
Output from the operator MMCVCAWeight.
+
value: T
+
The value matrix of shape (N, C, H, W).
+
+
+### Outputs
+
+
+
output: T
+
Output tensor of aggregated contextual information
+
+
+### Type Constraints
+
+- T:tensor(float32)
+
+## MMCVCornerPool
+
+### Description
+
+Perform CornerPool on `input` features. Read [CornerNet -- Detecting Objects as Paired Keypoints](https://arxiv.org/abs/1808.01244) for more details.
+
+### Parameters
+
+| Type | Parameter | Description |
+| ----- | --------- | ---------------------------------------------------------------- |
+| `int` | `mode` | corner pool mode, (0: `top`, 1: `bottom`, 2: `left`, 3: `right`) |
+
+### Inputs
+
+
+
input: T
+
Input features. 4-D tensor of shape (N, C, H, W). N is the batch size.
+
+
+### Outputs
+
+
+
output: T
+
The pooled features. 4-D tensor of shape (N, C, H, W).
+
+
+### Type Constraints
+
+- T:tensor(float32)
+
+## MMCVDeformConv2d
+
+### Description
+
+Applies a deformable 2D convolution over an input signal composed of several input planes.
+
+Read [Deformable Convolutional Networks](https://arxiv.org/pdf/1703.06211.pdf) for detail.
+
+### Parameters
+
+| Type | Parameter | Description |
+| -------------- | ------------------- | ----------------------------------------------------------------------------------------------------------------- |
+| `list of ints` | `stride` | The stride of the convolving kernel, (sH, sW). Defaults to `(1, 1)`. |
+| `list of ints` | `padding` | Paddings on both sides of the input, (padH, padW). Defaults to `(0, 0)`. |
+| `list of ints` | `dilation` | The spacing between kernel elements (dH, dW). Defaults to `(1, 1)`. |
+| `int` | `groups` | Split input into groups. `input_channel` should be divisible by the number of groups. Defaults to `1`. |
+| `int` | `deformable_groups` | Groups of deformable offset. Defaults to `1`. |
+| `int` | `bias` | Whether to add a learnable bias to the output. `0` stands for `False` and `1` stands for `True`. Defaults to `0`. |
+| `int` | `im2col_step` | Groups of deformable offset. Defaults to `32`. |
+
+### Inputs
+
+
+
input: T
+
Input feature; 4-D tensor of shape (N, C, inH, inW), where N is the batch size, C is the number of channels, inH and inW are the height and width of the data.
+
offset: T
+
Input offset; 4-D tensor of shape (N, deformable_group* 2* kH* kW, outH, outW), where kH and kW are the height and width of weight, outH and outW is the height and width of offset and output.
+
weight: T
+
Input weight; 4-D tensor of shape (output_channel, input_channel, kH, kW).
+
+
+### Outputs
+
+
+
output: T
+
Output feature; 4-D tensor of shape (N, output_channel, outH, outW).
+
+
+### Type Constraints
+
+- T:tensor(float32, Linear)
+
+## MMCVModulatedDeformConv2d
+
+### Description
+
+Perform Modulated Deformable Convolution on input feature, read [Deformable ConvNets v2: More Deformable, Better Results](https://arxiv.org/abs/1811.11168?from=timeline) for detail.
+
+### Parameters
+
+| Type | Parameter | Description |
+| -------------- | ------------------- | ------------------------------------------------------------------------------------- |
+| `list of ints` | `stride` | The stride of the convolving kernel. (sH, sW) |
+| `list of ints` | `padding` | Paddings on both sides of the input. (padH, padW) |
+| `list of ints` | `dilation` | The spacing between kernel elements. (dH, dW) |
+| `int` | `deformable_groups` | Groups of deformable offset. |
+| `int` | `groups` | Split input into groups. `input_channel` should be divisible by the number of groups. |
+
+### Inputs
+
+
+
feature: T
+
Input feature; 4-D tensor of shape (N, C, inH, inW), where N is the batch size, C is the number of channels, inH and inW are the height and width of the data.
+
offset: T
+
Input offset; 4-D tensor of shape (N, deformable_group* 2* kH* kW, outH, outW), where kH and kW are the height and width of weight, outH and outW are the height and width of offset and output.
+
mask: T
+
Input mask; 4-D tensor of shape (N, deformable_group* kH* kW, outH, outW), where kH and kW are the height and width of weight, outH and outW are the height and width of offset and output.
+
weight]: T
+
Input weight; 4-D tensor of shape (output_channel, input_channel, kH, kW).
+
bias: T, optional
+
Input bias; 1-D tensor of shape (output_channel).
+
+
+### Outputs
+
+
+
output: T
+
Output feature; 4-D tensor of shape (N, output_channel, outH, outW).
+
+
+### Type Constraints
+
+- T:tensor(float32, Linear)
+
+## MMCVDeformRoIPool
+
+### Description
+
+Deformable roi pooling layer
+
+### Parameters
+
+| Type | Parameter | Description |
+| ------- | ---------------- | ------------------------------------------------------------------------------------------------------------- |
+| `int` | `output_height` | height of output roi |
+| `int` | `output_width` | width of output roi |
+| `float` | `spatial_scale` | used to scale the input boxes |
+| `int` | `sampling_ratio` | number of input samples to take for each output sample. `0` means to take samples densely for current models. |
+| `float` | `gamma` | gamma |
+
+### Inputs
+
+
+
input: T
+
Input feature map; 4D tensor of shape (N, C, H, W), where N is the batch size, C is the numbers of channels, H and W are the height and width of the data.
+
rois: T
+
RoIs (Regions of Interest) to pool over; 2-D tensor of shape (num_rois, 5) given as [[batch_index, x1, y1, x2, y2], ...]. The RoIs' coordinates are the coordinate system of input.
+
offset: T
+
offset of height and width. Defaults to a tensor of zero
+
+
+### Outputs
+
+
+
feat: T
+
RoI pooled output, 4-D tensor of shape (num_rois, C, output_height, output_width). The r-th batch element feat[r-1] is a pooled feature map corresponding to the r-th RoI RoIs[r-1].
+
+
+### Type Constraints
+
+- T:tensor(float32)
+
+## MMCVMaskedConv2d
+
+### Description
+
+Performs a masked 2D convolution from PixelRNN
+Read [Pixel Recurrent Neural Networks](https://arxiv.org/abs/1601.06759) for more detailed information.
+
+### Parameters
+
+| Type | Parameter | Description |
+| -------------- | --------- | -------------------------------------------------------------------------------- |
+| `list of ints` | `stride` | The stride of the convolving kernel. (sH, sW). **Only support stride=1 in mmcv** |
+| `list of ints` | `padding` | Paddings on both sides of the input. (padH, padW). Defaults to `(0, 0)`. |
+
+### Inputs
+
+
+
features: T
+
Input features; 4D tensor of shape (N, C, H, W), where N is the batch size, C is the numbers of channels, H and W are the height and width of the data.
+
mask: T
+
Input mask; 3D tensor of shape (N, H, W)
+
weight: T
+
The learnable weights of the module
+
bias: T
+
The learnable bias of the module
+
+
+### Outputs
+
+
+
output: T
+
The output convolved feature
+
+
+### Type Constraints
+
+- T:tensor(float32)
+
+## MMCVPSAMask
+
+### Description
+
+An operator from PSANet.
+
+Read [PSANet: Point-wise Spatial Attention Network for Scene Parsing](https://hszhao.github.io/papers/eccv18_psanet.pdf) for more detailed information.
+
+### Parameters
+
+| Type | Parameter | Description |
+| -------------- | ----------- | -------------------------------------------- |
+| `int` | `psa_type` | `0` means collect and `1` means `distribute` |
+| `list of ints` | `mask_size` | The size of mask |
+
+### Inputs
+
+
+
input: T
+
Input feature; 4D tensor of shape (N, C, H, W), where N is the batch size, C is the numbers of channels, H and W are the height and width of the data.
+
+
+### Outputs
+
+
+
output: T
+
Output tensor of shape (N, H * W, H, W)
+
+
+### Type Constraints
+
+- T:tensor(float32)
+
+## NonMaxSuppression
+
+### Description
+
+Filter out boxes has high IoU overlap with previously selected boxes or low score. Output the indices of valid boxes.
+
+Note this definition is slightly different with [onnx: NonMaxSuppression](https://github.com/onnx/onnx/blob/master/docs/Operators.md#nonmaxsuppression)
+
+### Parameters
+
+| Type | Parameter | Description |
+| ------- | ---------------------------- | ------------------------------------------------------------------------------------------------------------------------------------ |
+| `int` | `center_point_box` | 0 - the box data is supplied as \[y1, x1, y2, x2\], 1-the box data is supplied as \[x_center, y_center, width, height\]. |
+| `int` | `max_output_boxes_per_class` | The maximum number of boxes to be selected per batch per class. Default to 0, number of output boxes equal to number of input boxes. |
+| `float` | `iou_threshold` | The threshold for deciding whether boxes overlap too much with respect to IoU. Value range \[0, 1\]. Default to 0. |
+| `float` | `score_threshold` | The threshold for deciding when to remove boxes based on score. |
+| `int` | `offset` | 0 or 1, boxes' width or height is (x2 - x1 + offset). |
+
+### Inputs
+
+
+
boxes: T
+
Input boxes. 3-D tensor of shape (num_batches, spatial_dimension, 4).
+
scores: T
+
Input scores. 3-D tensor of shape (num_batches, num_classes, spatial_dimension).
+
+
+### Outputs
+
+
+
indices: tensor(int32, Linear)
+
Selected indices. 2-D tensor of shape (num_selected_indices, 3) as [[batch_index, class_index, box_index], ...].
+
+### Type Constraints
+
+- T:tensor(float32, Linear)
+
+## MMCVRoIAlign
+
+### Description
+
+Perform RoIAlign on output feature, used in bbox_head of most two-stage detectors.
+
+### Parameters
+
+| Type | Parameter | Description |
+| ------- | ---------------- | ------------------------------------------------------------------------------------------------------------- |
+| `int` | `output_height` | height of output roi |
+| `int` | `output_width` | width of output roi |
+| `float` | `spatial_scale` | used to scale the input boxes |
+| `int` | `sampling_ratio` | number of input samples to take for each output sample. `0` means to take samples densely for current models. |
+| `str` | `mode` | pooling mode in each bin. `avg` or `max` |
+| `int` | `aligned` | If `aligned=0`, use the legacy implementation in MMDetection. Else, align the results more perfectly. |
+
+### Inputs
+
+
+
input: T
+
Input feature map; 4D tensor of shape (N, C, H, W), where N is the batch size, C is the numbers of channels, H and W are the height and width of the data.
+
rois: T
+
RoIs (Regions of Interest) to pool over; 2-D tensor of shape (num_rois, 5) given as [[batch_index, x1, y1, x2, y2], ...]. The RoIs' coordinates are the coordinate system of input.
+
+
+### Outputs
+
+
+
feat: T
+
RoI pooled output, 4-D tensor of shape (num_rois, C, output_height, output_width). The r-th batch element feat[r-1] is a pooled feature map corresponding to the r-th RoI RoIs[r-1].
+
+
+### Type Constraints
+
+- T:tensor(float32)
+
+## MMCVRoIAlignRotated
+
+### Description
+
+Perform RoI align pooling for rotated proposals
+
+### Parameters
+
+| Type | Parameter | Description |
+| ------- | ---------------- | ------------------------------------------------------------------------------------------------------------- |
+| `int` | `output_height` | height of output roi |
+| `int` | `output_width` | width of output roi |
+| `float` | `spatial_scale` | used to scale the input boxes |
+| `int` | `sampling_ratio` | number of input samples to take for each output sample. `0` means to take samples densely for current models. |
+| `str` | `mode` | pooling mode in each bin. `avg` or `max` |
+| `int` | `aligned` | If `aligned=0`, use the legacy implementation in MMDetection. Else, align the results more perfectly. |
+| `int` | `clockwise` | If `aligned=0`, use the legacy implementation in MMDetection. Else, align the results more perfectly. |
+
+### Inputs
+
+
RoIs (Regions of Interest) to pool over; 2-D tensor of shape (num_rois, 5) given as [[batch_index, x1, y1, x2, y2], ...]. The RoIs' coordinates are the coordinate system of input.
+
+
+### Outputs
+
+
+
RoI pooled output, 4-D tensor of shape (num_rois, C, output_height, output_width). The r-th batch element feat[r-1] is a pooled feature map corresponding to the r-th RoI RoIs[r-1].
+
+
+### Type Constraints
+
+- T:tensor(float32)
+
+## grid_sampler\*
+
+### Description
+
+Perform sample from `input` with pixel locations from `grid`.
+
+Check [torch.nn.functional.grid_sample](https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html?highlight=grid_sample#torch.nn.functional.grid_sample) for more information.
+
+### Parameters
+
+| Type | Parameter | Description |
+| ----- | -------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `int` | `interpolation_mode` | Interpolation mode to calculate output values. (0: `bilinear` , 1: `nearest`) |
+| `int` | `padding_mode` | Padding mode for outside grid values. (0: `zeros`, 1: `border`, 2: `reflection`) |
+| `int` | `align_corners` | If `align_corners=1`, the extrema (`-1` and `1`) are considered as referring to the center points of the input's corner pixels. If `align_corners=0`, they are instead considered as referring to the corner points of the input's corner pixels, making the sampling more resolution agnostic. |
+
+### Inputs
+
+
+
input: T
+
Input feature; 4-D tensor of shape (N, C, inH, inW), where N is the batch size, C is the numbers of channels, inH and inW are the height and width of the data.
+
grid: T
+
Input offset; 4-D tensor of shape (N, outH, outW, 2), where outH and outW are the height and width of offset and output.
+
+
+### Outputs
+
+
+
output: T
+
Output feature; 4-D tensor of shape (N, C, outH, outW).
+
+
+### Type Constraints
+
+- T:tensor(float32, Linear)
+
+## cummax\*
+
+### Description
+
+Returns a tuple (`values`, `indices`) where `values` is the cumulative maximum elements of `input` in the dimension `dim`. And `indices` is the index location of each maximum value found in the dimension `dim`. Read [torch.cummax](https://pytorch.org/docs/stable/generated/torch.cummax.html) for more details.
+
+### Parameters
+
+| Type | Parameter | Description |
+| ----- | --------- | -------------------------------------- |
+| `int` | `dim` | the dimension to do the operation over |
+
+### Inputs
+
+
+
input: T
+
The input tensor with various shapes. Tensor with empty element is also supported.
+
+
+### Outputs
+
+
+
output: T
+
Output the cumulative maximum elements of `input` in the dimension `dim`, with the same shape and dtype as `input`.
+
indices: tensor(int64)
+
Output the index location of each cumulative maximum value found in the dimension `dim`, with the same shape as `input`.
+
+
+### Type Constraints
+
+- T:tensor(float32)
+
+## cummin\*
+
+### Description
+
+Returns a tuple (`values`, `indices`) where `values` is the cumulative minimum elements of `input` in the dimension `dim`. And `indices` is the index location of each minimum value found in the dimension `dim`. Read [torch.cummin](https://pytorch.org/docs/stable/generated/torch.cummin.html) for more details.
+
+### Parameters
+
+| Type | Parameter | Description |
+| ----- | --------- | -------------------------------------- |
+| `int` | `dim` | the dimension to do the operation over |
+
+### Inputs
+
+
+
input: T
+
The input tensor with various shapes. Tensor with empty element is also supported.
+
+
+### Outputs
+
+
+
output: T
+
Output the cumulative minimum elements of `input` in the dimension `dim`, with the same shape and dtype as `input`.
+
indices: tensor(int64)
+
Output the index location of each cumulative minimum value found in the dimension `dim`, with the same shape as `input`.
+
+
+### Type Constraints
+
+- T:tensor(float32)
+
+## Reminders
+
+- Operators endwith `*` are defined in Torch and are included here for the conversion to ONNX.
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/en/docutils.conf b/cv/distiller/CWD/pytorch/mmcv/docs/en/docutils.conf
new file mode 100644
index 0000000000000000000000000000000000000000..0c00c84688701117f231fd0c8ec295fb747b7d8f
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/en/docutils.conf
@@ -0,0 +1,2 @@
+[html writers]
+table_style: colwidths-auto
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/en/faq.md b/cv/distiller/CWD/pytorch/mmcv/docs/en/faq.md
new file mode 100644
index 0000000000000000000000000000000000000000..02d31c233a9ff66d5e8f3f288b5d5f64e5c5298c
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/en/faq.md
@@ -0,0 +1,93 @@
+## Frequently Asked Questions
+
+We list some common troubles faced by many users and their corresponding solutions here.
+Feel free to enrich the list if you find any frequent issues and have ways to help others to solve them.
+
+### Installation
+
+- KeyError: "xxx: 'yyy is not in the zzz registry'"
+
+ The registry mechanism will be triggered only when the file of the module is imported.
+ So you need to import that file somewhere. More details can be found at [KeyError: "MaskRCNN: 'RefineRoIHead is not in the models registry'"](https://github.com/open-mmlab/mmdetection/issues/5974).
+
+- "No module named 'mmcv.ops'"; "No module named 'mmcv.\_ext'"
+
+ 1. Uninstall existing mmcv in the environment using `pip uninstall mmcv`
+ 2. Install mmcv-full following the [installation instruction](https://mmcv.readthedocs.io/en/latest/get_started/installation.html) or [Build MMCV from source](https://mmcv.readthedocs.io/en/latest/get_started/build.html)
+
+- "invalid device function" or "no kernel image is available for execution"
+
+ 1. Check the CUDA compute capability of you GPU
+ 2. Run `python mmdet/utils/collect_env.py` to check whether PyTorch, torchvision, and MMCV are built for the correct GPU architecture. You may need to set `TORCH_CUDA_ARCH_LIST` to reinstall MMCV. The compatibility issue could happen when using old GPUS, e.g., Tesla K80 (3.7) on colab.
+ 3. Check whether the running environment is the same as that when mmcv/mmdet is compiled. For example, you may compile mmcv using CUDA 10.0 bug run it on CUDA9.0 environments
+
+- "undefined symbol" or "cannot open xxx.so"
+
+ 1. If those symbols are CUDA/C++ symbols (e.g., libcudart.so or GLIBCXX), check
+ whether the CUDA/GCC runtimes are the same as those used for compiling mmcv
+ 2. If those symbols are Pytorch symbols (e.g., symbols containing caffe, aten, and TH), check whether the Pytorch version is the same as that used for compiling mmcv
+ 3. Run `python mmdet/utils/collect_env.py` to check whether PyTorch, torchvision, and MMCV are built by and running on the same environment
+
+- "RuntimeError: CUDA error: invalid configuration argument"
+
+ This error may be caused by the poor performance of GPU. Try to decrease the value of [THREADS_PER_BLOCK](https://github.com/open-mmlab/mmcv/blob/cac22f8cf5a904477e3b5461b1cc36856c2793da/mmcv/ops/csrc/common_cuda_helper.hpp#L10)
+ and recompile mmcv.
+
+- "RuntimeError: nms is not compiled with GPU support"
+
+ This error is because your CUDA environment is not installed correctly.
+ You may try to re-install your CUDA environment and then delete the build/ folder before re-compile mmcv.
+
+- "Segmentation fault"
+
+ 1. Check your GCC version and use GCC >= 5.4. This usually caused by the incompatibility between PyTorch and the environment (e.g., GCC \< 4.9 for PyTorch). We also recommend the users to avoid using GCC 5.5 because many feedbacks report that GCC 5.5 will cause "segmentation fault" and simply changing it to GCC 5.4 could solve the problem
+ 2. Check whether PyTorch is correctly installed and could use CUDA op, e.g. type the following command in your terminal and see whether they could correctly output results
+ ```shell
+ python -c 'import torch; print(torch.cuda.is_available())'
+ ```
+ 3. If PyTorch is correctly installed, check whether MMCV is correctly installed. If MMCV is correctly installed, then there will be no issue of the command
+ ```shell
+ python -c 'import mmcv; import mmcv.ops'
+ ```
+ 4. If MMCV and PyTorch are correctly installed, you can use `ipdb` to set breakpoints or directly add `print` to debug and see which part leads the `segmentation fault`
+
+- "libtorch_cuda_cu.so: cannot open shared object file"
+
+ `mmcv-full` depends on the share object but it can not be found. We can check whether the object exists in `~/miniconda3/envs/{environment-name}/lib/python3.7/site-packages/torch/lib` or try to re-install the PyTorch.
+
+- "fatal error C1189: #error: -- unsupported Microsoft Visual Studio version!"
+
+ If you are building mmcv-full on Windows and the version of CUDA is 9.2, you will probably encounter the error `"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.2\include\crt/host_config.h(133): fatal error C1189: #error: -- unsupported Microsoft Visual Studio version! Only the versions 2012, 2013, 2015 and 2017 are supported!"`, in which case you can use a lower version of Microsoft Visual Studio like vs2017.
+
+- "error: member "torch::jit::detail::ModulePolicy::all_slots" may not be initialized"
+
+ If your version of PyTorch is 1.5.0 and you are building mmcv-full on Windows, you will probably encounter the error `- torch/csrc/jit/api/module.h(474): error: member "torch::jit::detail::ModulePolicy::all_slots" may not be initialized`. The way to solve the error is to replace all the `static constexpr bool all_slots = false;` with `static bool all_slots = false;` at this file `https://github.com/pytorch/pytorch/blob/v1.5.0/torch/csrc/jit/api/module.h`. More details can be found at [member "torch::jit::detail::AttributePolicy::all_slots" may not be initialized](https://github.com/pytorch/pytorch/issues/39394).
+
+- "error: a member with an in-class initializer must be const"
+
+ If your version of PyTorch is 1.6.0 and you are building mmcv-full on Windows, you will probably encounter the error `"- torch/include\torch/csrc/jit/api/module.h(483): error: a member with an in-class initializer must be const"`. The way to solve the error is to replace all the `CONSTEXPR_EXCEPT_WIN_CUDA ` with `const` at `torch/include\torch/csrc/jit/api/module.h`. More details can be found at [Ninja: build stopped: subcommand failed](https://github.com/open-mmlab/mmcv/issues/575).
+
+- "error: member "torch::jit::ProfileOptionalOp::Kind" may not be initialized"
+
+ If your version of PyTorch is 1.7.0 and you are building mmcv-full on Windows, you will probably encounter the error `torch/include\torch/csrc/jit/ir/ir.h(1347): error: member "torch::jit::ProfileOptionalOp::Kind" may not be initialized`. The way to solve the error needs to modify several local files of PyTorch:
+
+ - delete `static constexpr Symbol Kind = ::c10::prim::profile;` and `tatic constexpr Symbol Kind = ::c10::prim::profile_optional;` at `torch/include\torch/csrc/jit/ir/ir.h`
+ - replace `explicit operator type&() { return *(this->value); }` with `explicit operator type&() { return *((type*)this->value); }` at `torch\include\pybind11\cast.h`
+ - replace all the `CONSTEXPR_EXCEPT_WIN_CUDA` with `const` at `torch/include\torch/csrc/jit/api/module.h`
+
+ More details can be found at [Ensure default extra_compile_args](https://github.com/pytorch/pytorch/pull/45956).
+
+- Compatibility issue between MMCV and MMDetection; "ConvWS is already registered in conv layer"
+
+ Please install the correct version of MMCV for the version of your MMDetection following the [installation instruction](https://mmdetection.readthedocs.io/en/latest/get_started.html#installation).
+
+### Usage
+
+- "RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one"
+
+ 1. This error indicates that your module has parameters that were not used in producing loss. This phenomenon may be caused by running different branches in your code in DDP mode. More datails at [Expected to have finished reduction in the prior iteration before starting a new one](https://github.com/pytorch/pytorch/issues/55582).
+ 2. You can set ` find_unused_parameters = True` in the config to solve the above problems or find those unused parameters manually
+
+- "RuntimeError: Trying to backward through the graph a second time"
+
+ `GradientCumulativeOptimizerHook` and `OptimizerHook` are both set which causes the `loss.backward()` to be called twice so `RuntimeError` was raised. We can only use one of these. More datails at [Trying to backward through the graph a second time](https://github.com/open-mmlab/mmcv/issues/1379).
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/en/get_started/build.md b/cv/distiller/CWD/pytorch/mmcv/docs/en/get_started/build.md
new file mode 100644
index 0000000000000000000000000000000000000000..e3d48ec7cf486edece6ea9e622937b08602f5e6e
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/en/get_started/build.md
@@ -0,0 +1,292 @@
+## Build MMCV from source
+
+### Build mmcv
+
+Before installing mmcv, make sure that PyTorch has been successfully installed following the [PyTorch official installation guide](https://pytorch.org/get-started/locally/#start-locally). This can be verified using the following command
+
+```bash
+python -c 'import torch;print(torch.__version__)'
+```
+
+If version information is output, then PyTorch is installed.
+
+```{note}
+If you would like to use `opencv-python-headless` instead of `opencv-python`,
+e.g., in a minimum container environment or servers without GUI,
+you can first install it before installing MMCV to skip the installation of `opencv-python`.
+```
+
+#### Build on Linux
+
+1. Clone the repo
+
+ ```bash
+ git clone https://github.com/open-mmlab/mmcv.git
+ cd mmcv
+ ```
+
+2. Install `ninja` and `psutil` to speed up the compilation
+
+ ```bash
+ pip install -r requirements/optional.txt
+ ```
+
+3. Check the nvcc version (requires 9.2+. Skip if no GPU available.)
+
+ ```bash
+ nvcc --version
+ ```
+
+ If the above command outputs the following message, it means that the nvcc setting is OK, otherwise you need to set CUDA_HOME.
+
+ ```
+ nvcc: NVIDIA (R) Cuda compiler driver
+ Copyright (c) 2005-2020 NVIDIA Corporation
+ Built on Mon_Nov_30_19:08:53_PST_2020
+ Cuda compilation tools, release 11.2, V11.2.67
+ Build cuda_11.2.r11.2/compiler.29373293_0
+ ```
+
+ :::{note}
+ If you want to support ROCm, you can refer to [AMD ROCm](https://rocmdocs.amd.com/en/latest/Installation_Guide/Installation-Guide.html) to install ROCm.
+ :::
+
+4. Check the gcc version (requires 5.4+)
+
+ ```bash
+ gcc --version
+ ```
+
+5. Start building (takes 10+ min)
+
+ ```bash
+ pip install -e . -v
+ ```
+
+6. Validate the installation
+
+ ```bash
+ python .dev_scripts/check_installation.py
+ ```
+
+ If no error is reported by the above command, the installation is successful. If there is an error reported, please check [Frequently Asked Questions](../faq.md) to see if there is already a solution.
+
+ If no solution is found, please feel free to open an [issue](https://github.com/open-mmlab/mmcv/issues).
+
+#### Build on macOS
+
+```{note}
+If you are using a mac with apple silicon chip, install the PyTorch 1.13+, otherwise you will encounter the problem in [issues#2218](https://github.com/open-mmlab/mmcv/issues/2218).
+```
+
+1. Clone the repo
+
+ ```bash
+ git clone https://github.com/open-mmlab/mmcv.git
+ cd mmcv
+ ```
+
+2. Install `ninja` and `psutil` to speed up the compilation
+
+ ```bash
+ pip install -r requirements/optional.txt
+ ```
+
+3. Start building
+
+ ```bash
+ MMCV_WITH_OPS=1 pip install -e .
+ ```
+
+4. Validate the installation
+
+ ```bash
+ python .dev_scripts/check_installation.py
+ ```
+
+ If no error is reported by the above command, the installation is successful. If there is an error reported, please check [Frequently Asked Questions](../faq.md) to see if there is already a solution.
+
+ If no solution is found, please feel free to open an [issue](https://github.com/open-mmlab/mmcv/issues).
+
+#### Build on Windows
+
+Building MMCV on Windows is a bit more complicated than that on Linux.
+The following instructions show how to get this accomplished.
+
+##### Prerequisite
+
+The following software is required for building MMCV on windows.
+Install them first.
+
+- [Git](https://git-scm.com/download/win)
+ - During installation, tick **add git to Path**.
+- [Visual Studio Community 2019](https://visualstudio.microsoft.com)
+ - A compiler for C++ and CUDA codes.
+- [Miniconda](https://docs.conda.io/en/latest/miniconda.html)
+ - Official distributions of Python should work too.
+- [CUDA 10.2](https://developer.nvidia.com/cuda-10.2-download-archive)
+ - Not required for building CPU version.
+ - Customize the installation if necessary. As a recommendation, skip the driver installation if a newer version is already installed.
+
+```{note}
+You should know how to set up environment variables, especially `Path`, on Windows. The following instruction relies heavily on this skill.
+```
+
+##### Common steps
+
+1. Launch Anaconda prompt from Windows Start menu
+
+ Do not use raw `cmd.exe` s instruction is based on PowerShell syntax.
+
+2. Create a new conda environment
+
+ ```powershell
+ (base) PS C:\Users\xxx> conda create --name mmcv python=3.7
+ (base) PS C:\Users\xxx> conda activate mmcv # make sure to activate environment before any operation
+ ```
+
+3. Install PyTorch. Choose a version based on your need.
+
+ ```powershell
+ # CUDA version
+ (mmcv) PS C:\Users\xxx> conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
+ # CPU version
+ (mmcv) PS C:\Users\xxx> conda install install pytorch torchvision cpuonly -c pytorch
+ ```
+
+4. Clone the repo
+
+ ```powershell
+ (mmcv) PS C:\Users\xxx> git clone https://github.com/open-mmlab/mmcv.git
+ (mmcv) PS C:\Users\xxx\mmcv> cd mmcv
+ ```
+
+5. Install `ninja` and `psutil` to speed up the compilation
+
+ ```powershell
+ (mmcv) PS C:\Users\xxx\mmcv> pip install -r requirements/optional.txt
+ ```
+
+6. Set up MSVC compiler
+
+ Set Environment variable, add `C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.27.29110\bin\Hostx86\x64` to `PATH`, so that `cl.exe` will be available in prompt, as shown below.
+
+ ```powershell
+ (mmcv) PS C:\Users\xxx\mmcv> cl
+ Microsoft (R) C/C++ Optimizing Compiler Version 19.27.29111 for x64
+ Copyright (C) Microsoft Corporation. All rights reserved.
+
+ usage: cl [ option... ] filename... [ / link linkoption... ]
+ ```
+
+ For compatibility, we use the x86-hosted and x64-targeted compiler. note `Hostx86\x64` in the path.
+
+ You may want to change the system language to English because pytorch will parse text output from `cl.exe` to check its version. However only utf-8 is recognized. Navigate to Control Panel -> Region -> Administrative -> Language for Non-Unicode programs and change it to English.
+
+##### Build and install MMCV
+
+mmcv can be built in two ways:
+
+1. Full version (CPU ops)
+
+ Module `ops` will be compiled as a pytorch extension, but only x86 code will be compiled. The compiled ops can be executed on CPU only.
+
+2. Full version (CUDA ops)
+
+ Both x86 and CUDA codes of `ops` module will be compiled. The compiled version can be run on both CPU and CUDA-enabled GPU (if implemented).
+
+###### CPU version
+
+Build and install
+
+```powershell
+(mmcv) PS C:\Users\xxx\mmcv> python setup.py build_ext
+(mmcv) PS C:\Users\xxx\mmcv> python setup.py develop
+```
+
+###### GPU version
+
+1. Make sure `CUDA_PATH` or `CUDA_HOME` is already set in `envs` via `ls env:`, desired output is shown as below:
+
+ ```powershell
+ (mmcv) PS C:\Users\xxx\mmcv> ls env:
+
+ Name Value
+ ---- -----
+ CUDA_PATH C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2
+ CUDA_PATH_V10_1 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1
+ CUDA_PATH_V10_2 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2
+ ```
+
+ This should already be done by CUDA installer. If not, or you have multiple version of CUDA toolkit installed, set it with
+
+ ```powershell
+ (mmcv) PS C:\Users\xxx\mmcv> $env:CUDA_HOME = "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2"
+ # OR
+ (mmcv) PS C:\Users\xxx\mmcv> $env:CUDA_HOME = $env:CUDA_PATH_V10_2 # if CUDA_PATH_V10_2 is in envs:
+ ```
+
+2. Set CUDA target arch
+
+ ```shell
+ # Here you need to change to the target architecture corresponding to your GPU
+ (mmcv) PS C:\Users\xxx\mmcv> $env:TORCH_CUDA_ARCH_LIST="7.5"
+ ```
+
+ :::{note}
+ Check your the compute capability of your GPU from [here](https://developer.nvidia.com/cuda-gpus).
+
+ ```powershell
+ (mmcv) PS C:\Users\xxx\mmcv> &"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\extras\demo_suite\deviceQuery.exe"
+ Device 0: "NVIDIA GeForce GTX 1660 SUPER"
+ CUDA Driver Version / Runtime Version 11.7 / 11.1
+ CUDA Capability Major/Minor version number: 7.5
+ ```
+
+ The 7.5 above indicates the target architecture. Note: You need to replace v10.2 with your CUDA version in the above command.
+ :::
+
+3. Build and install
+
+ ```powershell
+ # build
+ python setup.py build_ext # if success, cl will be launched to compile ops
+ # install
+ python setup.py develop
+ ```
+
+ ```{note}
+ If you are compiling against PyTorch 1.6.0, you might meet some errors from PyTorch as described in [this issue](https://github.com/pytorch/pytorch/issues/42467). Follow [this pull request](https://github.com/pytorch/pytorch/pull/43380/files) to modify the source code in your local PyTorch installation.
+ ```
+
+##### Validate installation
+
+```powershell
+(mmcv) PS C:\Users\xxx\mmcv> python .dev_scripts/check_installation.py
+```
+
+If no error is reported by the above command, the installation is successful. If there is an error reported, please check [Frequently Asked Questions](../faq.md) to see if there is already a solution.
+If no solution is found, please feel free to open an [issue](https://github.com/open-mmlab/mmcv/issues).
+
+### Build mmcv-lite
+
+If you need to use PyTorch-related modules, make sure PyTorch has been successfully installed in your environment by referring to the [PyTorch official installation guide](https://github.com/pytorch/pytorch#installation).
+
+1. Clone the repo
+
+ ```bash
+ git clone https://github.com/open-mmlab/mmcv.git
+ cd mmcv
+ ```
+
+2. Start building
+
+ ```bash
+ MMCV_WITH_OPS=0 pip install -e . -v
+ ```
+
+3. Validate installation
+
+ ```bash
+ python -c 'import mmcv;print(mmcv.__version__)'
+ ```
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/en/get_started/installation.md b/cv/distiller/CWD/pytorch/mmcv/docs/en/get_started/installation.md
new file mode 100644
index 0000000000000000000000000000000000000000..12bad000a171c0adf5be01dc7f53a94a5933070d
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/en/get_started/installation.md
@@ -0,0 +1,348 @@
+## Installation
+
+There are two versions of MMCV:
+
+- **mmcv**: comprehensive, with full features and various CUDA ops out of box. It takes longer time to build.
+- **mmcv-lite**: lite, without CUDA ops but all other features, similar to mmcv\<1.0.0. It is useful when you do not need those CUDA ops.
+
+```{warning}
+Do not install both versions in the same environment, otherwise you may encounter errors like `ModuleNotFound`. You need to uninstall one before installing the other. `Installing the full version is highly recommended if CUDA is avaliable`.
+```
+
+### Install mmcv
+
+Before installing mmcv, make sure that PyTorch has been successfully installed following the [PyTorch official installation guide](https://pytorch.org/get-started/locally/#start-locally). This can be verified using the following command
+
+```bash
+python -c 'import torch;print(torch.__version__)'
+```
+
+If version information is output, then PyTorch is installed.
+
+#### Install with mim (recommended)
+
+[mim](https://github.com/open-mmlab/mim) is the package management tool for the OpenMMLab projects, which makes it easy to install mmcv
+
+```bash
+pip install -U openmim
+mim install "mmcv>=2.0.0rc1"
+```
+
+If you find that the above installation command does not use a pre-built package ending with `.whl` but a source package ending with `.tar.gz`, you may not have a pre-build package corresponding to the PyTorch or CUDA or mmcv version, in which case you can [build mmcv from source](build.md).
+
+
+Installation log using pre-built packages
+
+Looking in links: https://download.openmmlab.com/mmcv/dist/cu102/torch1.8.0/index.html
+Collecting mmcv
+Downloading https://download.openmmlab.com/mmcv/dist/cu102/torch1.8.0/mmcv-2.0.0rc3-cp38-cp38-manylinux1_x86_64.whl
+
+
+
+
+Installation log using source packages
+
+Looking in links: https://download.openmmlab.com/mmcv/dist/cu102/torch1.8.0/index.html
+Collecting mmcv==2.0.0rc3
+Downloading mmcv-2.0.0rc3.tar.gz
+
+
+
+To install a specific version of mmcv, for example, mmcv version 2.0.0rc3, you can use the following command
+
+```bash
+mim install mmcv==2.0.0rc3
+```
+
+:::{note}
+If you would like to use `opencv-python-headless` instead of `opencv-python`,
+e.g., in a minimum container environment or servers without GUI,
+you can first install it before installing MMCV to skip the installation of `opencv-python`.
+
+Alternatively, if it takes too long to install a dependency library, you can specify the pypi source
+
+```bash
+mim install "mmcv>=2.0.0rc3" -i https://pypi.tuna.tsinghua.edu.cn/simple
+```
+
+:::
+
+You can run [check_installation.py](https://github.com/open-mmlab/mmcv/blob/2.x/.dev_scripts/check_installation.py) to check the installation of mmcv-full after running the installation commands.
+
+#### Install with pip
+
+Use the following command to check the version of CUDA and PyTorch
+
+```bash
+python -c 'import torch;print(torch.__version__);print(torch.version.cuda)'
+```
+
+Select the appropriate installation command depending on the type of system, CUDA version, PyTorch version, and MMCV version
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+If you do not find a corresponding version in the dropdown box above, you probably do not have a pre-built package corresponding to the PyTorch or CUDA or mmcv version, at which point you can [build mmcv from source](build.md).
+
+:::{note}
+mmcv is only compiled on PyTorch 1.x.0 because the compatibility
+usually holds between 1.x.0 and 1.x.1. If your PyTorch version is 1.x.1, you
+can install mmcv compiled with PyTorch 1.x.0 and it usually works well.
+For example, if your PyTorch version is 1.8.1, you can feel free to choose 1.8.x.
+:::
+
+:::{note}
+If you would like to use `opencv-python-headless` instead of `opencv-python`,
+e.g., in a minimum container environment or servers without GUI,
+you can first install it before installing MMCV to skip the installation of `opencv-python`.
+
+Alternatively, if it takes too long to install a dependency library, you can specify the pypi source
+
+```bash
+mim install "mmcv>=2.0.0rc1" -i https://pypi.tuna.tsinghua.edu.cn/simple
+```
+
+:::
+
+You can run [check_installation.py](https://github.com/open-mmlab/mmcv/blob/2.x/.dev_scripts/check_installation.py) to check the installation of mmcv after running the installation commands.
+
+#### Using mmcv with Docker
+
+Build with local repository
+
+```bash
+git clone https://github.com/open-mmlab/mmcv.git && cd mmcv
+docker build -t mmcv -f docker/release/Dockerfile .
+```
+
+Or build with remote repository
+
+```bash
+docker build -t mmcv https://github.com/open-mmlab/mmcv.git#2.x:docker/release
+```
+
+The [Dockerfile](release/Dockerfile) installs latest released version of mmcv-full by default, but you can specify mmcv versions to install expected versions.
+
+```bash
+docker image build -t mmcv -f docker/release/Dockerfile --build-arg MMCV=2.0.0rc1 .
+```
+
+If you also want to use other versions of PyTorch and CUDA, you can also pass them when building docker images.
+
+An example to build an image with PyTorch 1.11 and CUDA 11.3.
+
+```bash
+docker build -t mmcv -f docker/release/Dockerfile \
+ --build-arg PYTORCH=1.11.0 \
+ --build-arg CUDA=11.3 \
+ --build-arg CUDNN=8 \
+ --build-arg MMCV=2.0.0rc1 .
+```
+
+More available versions of PyTorch and CUDA can be found at [dockerhub/pytorch](https://hub.docker.com/r/pytorch/pytorch/tags).
+
+### Install mmcv-lite
+
+If you need to use PyTorch-related modules, make sure PyTorch has been successfully installed in your environment by referring to the [PyTorch official installation guide](https://github.com/pytorch/pytorch#installation).
+
+```python
+pip install mmcv-lite
+```
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/en/get_started/introduction.md b/cv/distiller/CWD/pytorch/mmcv/docs/en/get_started/introduction.md
new file mode 100644
index 0000000000000000000000000000000000000000..461fcc725bbcf4a84296e95789303b64e7b2e9c5
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/en/get_started/introduction.md
@@ -0,0 +1,36 @@
+## Introduction
+
+MMCV is a foundational library for computer vision research and provides the following functionalities.
+
+- [Image/Video processing](../understand_mmcv/data_process.md)
+- [Image and annotation visualization](../understand_mmcv/visualization.md)
+- [Image transformation](../understand_mmcv/data_transform.md)
+- [Various CNN architectures](../understand_mmcv/cnn.md)
+- [High-quality implementation of common CUDA ops](../understand_mmcv/ops.md)
+
+It supports the following systems:
+
+- Linux
+- Windows
+- macOS
+
+It supports many research projects as below:
+
+- [MMClassification](https://github.com/open-mmlab/mmclassification): OpenMMLab image classification toolbox and benchmark.
+- [MMDetection](https://github.com/open-mmlab/mmdetection): OpenMMLab detection toolbox and benchmark.
+- [MMDetection3D](https://github.com/open-mmlab/mmdetection3d): OpenMMLab's next-generation platform for general 3D object detection.
+- [MMRotate](https://github.com/open-mmlab/mmrotate): OpenMMLab rotated object detection toolbox and benchmark.
+- [MMYOLO](https://github.com/open-mmlab/mmyolo): OpenMMLab YOLO series toolbox and benchmark.
+- [MMSegmentation](https://github.com/open-mmlab/mmsegmentation): OpenMMLab semantic segmentation toolbox and benchmark.
+- [MMOCR](https://github.com/open-mmlab/mmocr): OpenMMLab text detection, recognition, and understanding toolbox.
+- [MMPose](https://github.com/open-mmlab/mmpose): OpenMMLab pose estimation toolbox and benchmark.
+- [MMHuman3D](https://github.com/open-mmlab/mmhuman3d): OpenMMLab 3D human parametric model toolbox and benchmark.
+- [MMSelfSup](https://github.com/open-mmlab/mmselfsup): OpenMMLab self-supervised learning toolbox and benchmark.
+- [MMRazor](https://github.com/open-mmlab/mmrazor): OpenMMLab model compression toolbox and benchmark.
+- [MMFewShot](https://github.com/open-mmlab/mmfewshot): OpenMMLab fewshot learning toolbox and benchmark.
+- [MMAction2](https://github.com/open-mmlab/mmaction2): OpenMMLab's next-generation action understanding toolbox and benchmark.
+- [MMTracking](https://github.com/open-mmlab/mmtracking): OpenMMLab video perception toolbox and benchmark.
+- [MMFlow](https://github.com/open-mmlab/mmflow): OpenMMLab optical flow toolbox and benchmark.
+- [MMEditing](https://github.com/open-mmlab/mmediting): OpenMMLab image and video editing toolbox.
+- [MMGeneration](https://github.com/open-mmlab/mmgeneration): OpenMMLab image and video generative models toolbox.
+- [MMDeploy](https://github.com/open-mmlab/mmdeploy): OpenMMLab model deployment framework.
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/en/get_started/previous_versions.md b/cv/distiller/CWD/pytorch/mmcv/docs/en/get_started/previous_versions.md
new file mode 100644
index 0000000000000000000000000000000000000000..a9c3717667fec3e8f338c319413aa6ad639dc6d3
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/en/get_started/previous_versions.md
@@ -0,0 +1,47 @@
+## OTHER VERSIONS OF PYTORCH BUILT FOR MMCV-FULL
+
+We no longer provide `mmcv-full` packages compiled under lower versions of `PyTorch`, but for your convenience, you can find them below.
+
+### PyTorch 1.4
+
+| 1.0.0 \<= mmcv_version \<= 1.2.1
+
+#### CUDA 10.1
+
+```bash
+pip install mmcv-full=={mmcv_version} -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.4.0/index.html
+```
+
+#### CUDA 9.2
+
+```bash
+pip install mmcv-full=={mmcv_version} -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.4.0/index.html
+```
+
+#### CPU
+
+```bash
+pip install mmcv-full=={mmcv_version} -f https://download.openmmlab.com/mmcv/dist/cpu/torch1.4.0/index.html
+```
+
+### PyTorch v1.3
+
+| 1.0.0 \<= mmcv_version \<= 1.3.16
+
+#### CUDA 10.1
+
+```bash
+pip install mmcv-full=={mmcv_version} -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.3.0/index.html
+```
+
+#### CUDA 9.2
+
+```bash
+pip install mmcv-full=={mmcv_version} -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.3.0/index.html
+```
+
+#### CPU
+
+```bash
+pip install mmcv-full=={mmcv_version} -f https://download.openmmlab.com/mmcv/dist/cpu/torch1.3.0/index.html
+```
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/en/index.rst b/cv/distiller/CWD/pytorch/mmcv/docs/en/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..dee2c37507fb77df42fef5e51fe501214c13d7ce
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/en/index.rst
@@ -0,0 +1,69 @@
+Welcome to MMCV's documentation!
+================================
+
+You can switch between Chinese and English documents in the lower-left corner of the layout.
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Get Started
+
+ get_started/introduction.md
+ get_started/installation.md
+ get_started/build.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Understand MMCV
+
+ understand_mmcv/data_process.md
+ understand_mmcv/data_transform.md
+ understand_mmcv/visualization.md
+ understand_mmcv/cnn.md
+ understand_mmcv/ops.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Deployment
+
+ deployment/mmcv_ops_definition.md
+
+.. toctree::
+ :caption: Switch Language
+
+ switch_language.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Compatibility
+
+ compatibility.md
+
+.. toctree::
+
+ faq.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Community
+
+ community/contributing.md
+ community/pr.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: API Reference
+
+ mmcv.image
+ mmcv.video
+ mmcv.visualization
+ mmcv.cnn
+ mmcv.ops
+ mmcv.transforms
+ mmcv.arraymisc
+ mmcv.utils
+
+Indices and tables
+==================
+
+* :ref:`genindex`
+* :ref:`search`
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/en/make.bat b/cv/distiller/CWD/pytorch/mmcv/docs/en/make.bat
new file mode 100644
index 0000000000000000000000000000000000000000..7893348a1b7dbb588983a48e6991282eae7e1b55
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/en/make.bat
@@ -0,0 +1,35 @@
+@ECHO OFF
+
+pushd %~dp0
+
+REM Command file for Sphinx documentation
+
+if "%SPHINXBUILD%" == "" (
+ set SPHINXBUILD=sphinx-build
+)
+set SOURCEDIR=.
+set BUILDDIR=_build
+
+if "%1" == "" goto help
+
+%SPHINXBUILD% >NUL 2>NUL
+if errorlevel 9009 (
+ echo.
+ echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
+ echo.installed, then set the SPHINXBUILD environment variable to point
+ echo.to the full path of the 'sphinx-build' executable. Alternatively you
+ echo.may add the Sphinx directory to PATH.
+ echo.
+ echo.If you don't have Sphinx installed, grab it from
+ echo.http://sphinx-doc.org/
+ exit /b 1
+)
+
+%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS%
+goto end
+
+:help
+%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS%
+
+:end
+popd
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/en/mmcv-logo.png b/cv/distiller/CWD/pytorch/mmcv/docs/en/mmcv-logo.png
new file mode 100644
index 0000000000000000000000000000000000000000..bcc5759f8fe3bc7d191d411c38a9e1d3c1c27a84
Binary files /dev/null and b/cv/distiller/CWD/pytorch/mmcv/docs/en/mmcv-logo.png differ
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/en/switch_language.md b/cv/distiller/CWD/pytorch/mmcv/docs/en/switch_language.md
new file mode 100644
index 0000000000000000000000000000000000000000..9dc7b34b4fac6a972abedd8c2b0b80d03441d2b9
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/en/switch_language.md
@@ -0,0 +1,3 @@
+## English
+
+## 简体中文
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/en/understand_mmcv/cnn.md b/cv/distiller/CWD/pytorch/mmcv/docs/en/understand_mmcv/cnn.md
new file mode 100644
index 0000000000000000000000000000000000000000..2c42f25d9d5c5b2886c420bbab4461272cf02b21
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/en/understand_mmcv/cnn.md
@@ -0,0 +1,120 @@
+## CNN
+
+We provide some building bricks for CNNs, including layer building, module bundles and weight initialization.
+
+### Layer building
+
+We may need to try different layers of the same type when running experiments,
+but do not want to modify the code from time to time.
+Here we provide some layer building methods to construct layers from a dict,
+which can be written in configs or specified via command line arguments.
+
+#### Usage
+
+A simplest example is
+
+```python
+from mmcv.cnn import build_conv_layer
+
+cfg = dict(type='Conv3d')
+layer = build_conv_layer(cfg, in_channels=3, out_channels=8, kernel_size=3)
+```
+
+- `build_conv_layer`: Supported types are Conv1d, Conv2d, Conv3d, Conv (alias for Conv2d).
+- `build_norm_layer`: Supported types are BN1d, BN2d, BN3d, BN (alias for BN2d), SyncBN, GN, LN, IN1d, IN2d, IN3d, IN (alias for IN2d).
+- `build_activation_layer`: Supported types are ReLU, LeakyReLU, PReLU, RReLU, ReLU6, ELU, Sigmoid, Tanh, GELU.
+- `build_upsample_layer`: Supported types are nearest, bilinear, deconv, pixel_shuffle.
+- `build_padding_layer`: Supported types are zero, reflect, replicate.
+
+#### Extension
+
+We also allow extending the building methods with custom layers and operators.
+
+1. Write and register your own module.
+
+ ```python
+ from mmengine.registry import MODELS
+
+ @MODELS.register_module()
+ class MyUpsample:
+
+ def __init__(self, scale_factor):
+ pass
+
+ def forward(self, x):
+ pass
+ ```
+
+2. Import `MyUpsample` somewhere (e.g., in `__init__.py`) and then use it.
+
+ ```python
+ from mmcv.cnn import build_upsample_layer
+
+ cfg = dict(type='MyUpsample', scale_factor=2)
+ layer = build_upsample_layer(cfg)
+ ```
+
+### Module bundles
+
+We also provide common module bundles to facilitate the network construction.
+`ConvModule` is a bundle of convolution, normalization and activation layers,
+please refer to the [api](api.html#mmcv.cnn.ConvModule) for details.
+
+```python
+from mmcv.cnn import ConvModule
+
+# conv + bn + relu
+conv = ConvModule(3, 8, 2, norm_cfg=dict(type='BN'))
+# conv + gn + relu
+conv = ConvModule(3, 8, 2, norm_cfg=dict(type='GN', num_groups=2))
+# conv + relu
+conv = ConvModule(3, 8, 2)
+# conv
+conv = ConvModule(3, 8, 2, act_cfg=None)
+# conv + leaky relu
+conv = ConvModule(3, 8, 3, padding=1, act_cfg=dict(type='LeakyReLU'))
+# bn + conv + relu
+conv = ConvModule(
+ 3, 8, 2, norm_cfg=dict(type='BN'), order=('norm', 'conv', 'act'))
+```
+
+### Model Zoo
+
+Besides torchvision pre-trained models, we also provide pre-trained models of following CNN:
+
+- VGG Caffe
+- ResNet Caffe
+- ResNeXt
+- ResNet with Group Normalization
+- ResNet with Group Normalization and Weight Standardization
+- HRNetV2
+- Res2Net
+- RegNet
+
+#### Model URLs in JSON
+
+The model zoo links in MMCV are managed by JSON files.
+The json file consists of key-value pair of model name and its url or path.
+An example json file could be like:
+
+```json
+{
+ "model_a": "https://example.com/models/model_a_9e5bac.pth",
+ "model_b": "pretrain/model_b_ab3ef2c.pth"
+}
+```
+
+The default links of the pre-trained models hosted on OpenMMLab AWS could be found [here](https://github.com/open-mmlab/mmcv/blob/master/mmcv/model_zoo/open_mmlab.json).
+
+You may override default links by putting `open-mmlab.json` under `MMCV_HOME`. If `MMCV_HOME` is not found in your environment, `~/.cache/mmcv` will be used by default. You may use your own path with `export MMCV_HOME=/your/path`.
+
+The external json files will be merged into default one. If the same key presents in both external json and default json, the external one will be used.
+
+#### Load Checkpoint
+
+The following types are supported for `filename` of `mmcv.load_checkpoint()`.
+
+- filepath: The filepath of the checkpoint.
+- `http://xxx` and `https://xxx`: The link to download the checkpoint. The `SHA256` postfix should be contained in the filename.
+- `torchvision://xxx`: The model links in `torchvision.models`. Please refer to [torchvision](https://pytorch.org/docs/stable/torchvision/models.html) for details.
+- `open-mmlab://xxx`: The model links or filepath provided in default and additional json files.
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/en/understand_mmcv/data_process.md b/cv/distiller/CWD/pytorch/mmcv/docs/en/understand_mmcv/data_process.md
new file mode 100644
index 0000000000000000000000000000000000000000..167928f88528ee6b682a559582a1584c369a5d39
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/en/understand_mmcv/data_process.md
@@ -0,0 +1,286 @@
+## Data Process
+
+### Image
+
+This module provides some image processing methods, which requires `opencv` to be installed first.
+
+#### Read/Write/Show
+
+To read or write images files, use `imread` or `imwrite`.
+
+```python
+import mmcv
+
+img = mmcv.imread('test.jpg')
+img = mmcv.imread('test.jpg', flag='grayscale')
+img_ = mmcv.imread(img) # nothing will happen, img_ = img
+mmcv.imwrite(img, 'out.jpg')
+```
+
+To read images from bytes
+
+```python
+with open('test.jpg', 'rb') as f:
+ data = f.read()
+img = mmcv.imfrombytes(data)
+```
+
+To show an image file or a loaded image
+
+```python
+mmcv.imshow('tests/data/color.jpg')
+# this is equivalent to
+
+for i in range(10):
+ img = np.random.randint(256, size=(100, 100, 3), dtype=np.uint8)
+ mmcv.imshow(img, win_name='test image', wait_time=200)
+```
+
+#### Color space conversion
+
+Supported conversion methods:
+
+- bgr2gray
+- gray2bgr
+- bgr2rgb
+- rgb2bgr
+- bgr2hsv
+- hsv2bgr
+
+```python
+img = mmcv.imread('tests/data/color.jpg')
+img1 = mmcv.bgr2rgb(img)
+img2 = mmcv.rgb2gray(img1)
+img3 = mmcv.bgr2hsv(img)
+```
+
+#### Resize
+
+There are three resize methods. All `imresize_*` methods have an argument `return_scale`,
+if this argument is `False`, then the return value is merely the resized image, otherwise
+is a tuple `(resized_img, scale)`.
+
+```python
+# resize to a given size
+mmcv.imresize(img, (1000, 600), return_scale=True)
+
+# resize to the same size of another image
+mmcv.imresize_like(img, dst_img, return_scale=False)
+
+# resize by a ratio
+mmcv.imrescale(img, 0.5)
+
+# resize so that the max edge no longer than 1000, short edge no longer than 800
+# without changing the aspect ratio
+mmcv.imrescale(img, (1000, 800))
+```
+
+#### Rotate
+
+To rotate an image by some angle, use `imrotate`. The center can be specified,
+which is the center of original image by default. There are two modes of rotating,
+one is to keep the image size unchanged so that some parts of the image will be
+cropped after rotating, the other is to extend the image size to fit the rotated
+image.
+
+```python
+img = mmcv.imread('tests/data/color.jpg')
+
+# rotate the image clockwise by 30 degrees.
+img_ = mmcv.imrotate(img, 30)
+
+# rotate the image counterclockwise by 90 degrees.
+img_ = mmcv.imrotate(img, -90)
+
+# rotate the image clockwise by 30 degrees, and rescale it by 1.5x at the same time.
+img_ = mmcv.imrotate(img, 30, scale=1.5)
+
+# rotate the image clockwise by 30 degrees, with (100, 100) as the center.
+img_ = mmcv.imrotate(img, 30, center=(100, 100))
+
+# rotate the image clockwise by 30 degrees, and extend the image size.
+img_ = mmcv.imrotate(img, 30, auto_bound=True)
+```
+
+#### Flip
+
+To flip an image, use `imflip`.
+
+```python
+img = mmcv.imread('tests/data/color.jpg')
+
+# flip the image horizontally
+mmcv.imflip(img)
+
+# flip the image vertically
+mmcv.imflip(img, direction='vertical')
+```
+
+#### Crop
+
+`imcrop` can crop the image with one or more regions. Each region is represented by the upper left and lower right coordinates as (x1, y1, x2, y2).
+
+```python
+import mmcv
+import numpy as np
+
+img = mmcv.imread('tests/data/color.jpg')
+
+# crop the region (10, 10, 100, 120)
+bboxes = np.array([10, 10, 100, 120])
+patch = mmcv.imcrop(img, bboxes)
+
+# crop two regions (10, 10, 100, 120) and (0, 0, 50, 50)
+bboxes = np.array([[10, 10, 100, 120], [0, 0, 50, 50]])
+patches = mmcv.imcrop(img, bboxes)
+
+# crop two regions, and rescale the patches by 1.2x
+patches = mmcv.imcrop(img, bboxes, scale=1.2)
+```
+
+#### Padding
+
+There are two methods, `impad` and `impad_to_multiple`, to pad an image to the
+specific size with given values.
+
+```python
+img = mmcv.imread('tests/data/color.jpg')
+
+# pad the image to (1000, 1200) with all zeros
+img_ = mmcv.impad(img, shape=(1000, 1200), pad_val=0)
+
+# pad the image to (1000, 1200) with different values for three channels.
+img_ = mmcv.impad(img, shape=(1000, 1200), pad_val=(100, 50, 200))
+
+# pad the image on left, right, top, bottom borders with all zeros
+img_ = mmcv.impad(img, padding=(10, 20, 30, 40), pad_val=0)
+
+# pad the image on left, right, top, bottom borders with different values
+# for three channels.
+img_ = mmcv.impad(img, padding=(10, 20, 30, 40), pad_val=(100, 50, 200))
+
+# pad an image so that each edge is a multiple of some value.
+img_ = mmcv.impad_to_multiple(img, 32)
+```
+
+### Video
+
+This module provides the following functionalities:
+
+- A `VideoReader` class with friendly apis to read and convert videos.
+- Some methods for editing (cut, concat, resize) videos.
+- Optical flow read/write/warp.
+
+#### VideoReader
+
+The `VideoReader` class provides sequence like apis to access video frames.
+It will internally cache the frames which have been visited.
+
+```python
+video = mmcv.VideoReader('test.mp4')
+
+# obtain basic information
+print(len(video))
+print(video.width, video.height, video.resolution, video.fps)
+
+# iterate over all frames
+for frame in video:
+ print(frame.shape)
+
+# read the next frame
+img = video.read()
+
+# read a frame by index
+img = video[100]
+
+# read some frames
+img = video[5:10]
+```
+
+To convert a video to images or generate a video from a image directory.
+
+```python
+# split a video into frames and save to a folder
+video = mmcv.VideoReader('test.mp4')
+video.cvt2frames('out_dir')
+
+# generate video from frames
+mmcv.frames2video('out_dir', 'test.avi')
+```
+
+#### Editing utils
+
+There are also some methods for editing videos, which wraps the commands of ffmpeg.
+
+```python
+# cut a video clip
+mmcv.cut_video('test.mp4', 'clip1.mp4', start=3, end=10, vcodec='h264')
+
+# join a list of video clips
+mmcv.concat_video(['clip1.mp4', 'clip2.mp4'], 'joined.mp4', log_level='quiet')
+
+# resize a video with the specified size
+mmcv.resize_video('test.mp4', 'resized1.mp4', (360, 240))
+
+# resize a video with a scaling ratio of 2
+mmcv.resize_video('test.mp4', 'resized2.mp4', ratio=2)
+```
+
+#### Optical flow
+
+`mmcv` provides the following methods to operate on optical flows.
+
+- IO
+- Visualization
+- Flow warping
+
+We provide two options to dump optical flow files: uncompressed and compressed.
+The uncompressed way just dumps the floating numbers to a binary file. It is
+lossless but the dumped file has a larger size.
+The compressed way quantizes the optical flow to 0-255 and dumps it as a
+jpeg image. The flow of x-dim and y-dim will be concatenated into a single image.
+
+1. IO
+
+```python
+flow = np.random.rand(800, 600, 2).astype(np.float32)
+# dump the flow to a flo file (~3.7M)
+mmcv.flowwrite(flow, 'uncompressed.flo')
+# dump the flow to a jpeg file (~230K)
+# the shape of the dumped image is (800, 1200)
+mmcv.flowwrite(flow, 'compressed.jpg', quantize=True, concat_axis=1)
+
+# read the flow file, the shape of loaded flow is (800, 600, 2) for both ways
+flow = mmcv.flowread('uncompressed.flo')
+flow = mmcv.flowread('compressed.jpg', quantize=True, concat_axis=1)
+```
+
+2. Visualization
+
+It is possible to visualize optical flows with `mmcv.flowshow()`.
+
+```python
+mmcv.flowshow(flow)
+```
+
+
+
+3. Flow warping
+
+```python
+img1 = mmcv.imread('img1.jpg')
+flow = mmcv.flowread('flow.flo')
+warped_img2 = mmcv.flow_warp(img1, flow)
+```
+
+img1 (left) and img2 (right)
+
+
+
+optical flow (img2 -> img1)
+
+
+
+warped image and difference with ground truth
+
+
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/en/understand_mmcv/data_transform.md b/cv/distiller/CWD/pytorch/mmcv/docs/en/understand_mmcv/data_transform.md
new file mode 100644
index 0000000000000000000000000000000000000000..64c3af980eab0b07d7a298cee2c41465803911f8
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/en/understand_mmcv/data_transform.md
@@ -0,0 +1,341 @@
+# Data Transformation
+
+In the OpenMMLab algorithm library, dataset construction and data preparation are decoupled. Usually, the construction of the dataset only parses the dataset and records the basic information of each sample, while the data preparation is a series of data transformations including data loading, preprocessing, formatting, and other operations performed according to the basic information of the sample.
+
+## Design of data transformation
+
+In MMCV, we use various callable data transformation classes to manipulate data. These data transformation classes can accept several configuration parameters for the instantiation and then process the input data dictionary by `__call__` method. All data transformation methods accept a dictionary as the input and produce the output as a dictionary as well. A simple example is as follows:
+
+```python
+>>> import numpy as np
+>>> from mmcv.transforms import Resize
+>>>
+>>> transform = Resize(scale=(224, 224))
+>>> data_dict = {'img': np.random.rand(256, 256, 3)}
+>>> data_dict = transform(data_dict)
+>>> print(data_dict['img'].shape)
+(224, 224, 3)
+```
+
+The data transformation class reads some fields of the input dictionary and may add or update some fields. The keys of these fields are mostly fixed. For example, `Resize` will always read fields such as `"img"` in the input dictionary. More information about the conventions for input and output fields could be found in the documentation of the corresponding class.
+
+```{note}
+By convention, the order of image shape which is used as **initialization parameters** in data transformation (such as Resize, Pad) is (width, height). In the dictionary returned by the data transformation, the image related shape, such as `img_shape`, `ori_shape`, `pad_shape`, etc., is (height, width).
+```
+
+MMCV provides a unified base class called `BaseTransform` for all data transformation classes:
+
+```python
+class BaseTransform(metaclass=ABCMeta):
+
+ def __call__(self, results: dict) -> dict:
+
+ return self.transform(results)
+
+ @abstractmethod
+ def transform(self, results: dict) -> dict:
+ pass
+```
+
+All data transformation classes must inherit `BaseTransform` and implement the `transform` method. Both the input and output of the `transform` method are a dictionary. In the **Custom data transformation class** section, we will describe how to implement a data transformation class in more detail.
+
+## Data pipeline
+
+As mentioned above, the inputs and outputs of all data transformations are dictionaries. Moreover, according to the \[Convention on Datasets\] (TODO) in OpenMMLab, the basic information of each sample in the dataset is also a dictionary. This way, we can connect all data transformation operations end to end and combine them into a data pipeline. This pipeline inputs the information dictionary of the samples in the dataset and outputs the information dictionary after a series of processing.
+
+Taking the classification task as an example, we show a typical data pipeline in the figure below. For each sample, the information stored in the dataset is a dictionary, as shown on the far left in the figure. After each data transformation operation represented by the blue block, a new field (marked in green) will be added to the data dictionary or an existing field (marked in orange) will be updated.
+
+
+
+
+
+The data pipeline is a list of several data transformation configuration dictionaries in the configuration file. Each dataset needs to set the parameter `pipeline` to define the data preparation operations the dataset needs to perform. The configuration of the above data pipeline in the configuration file is as follows:
+
+```python
+pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='Resize', size=256, keep_ratio=True),
+ dict(type='CenterCrop', crop_size=224),
+ dict(type='Normalize', mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375]),
+ dict(type='ClsFormatBundle')
+]
+
+dataset = dict(
+ ...
+ pipeline=pipeline,
+ ...
+)
+```
+
+## Common data transformation classes
+
+The commonly used data transformation classes can be roughly divided into data loading, data preprocessing and augmentation, and data formatting. In MMCV, we provide some commonly used classes as follows:
+
+### Data loading
+
+To support the loading of large-scale datasets, data is usually not loaded when `Dataset` is initialized. Only the corresponding path is loaded. Therefore, it is necessary to load specific data in the data pipeline.
+
+| Class | Feature |
+| :-------------------------: | :--------------------------------------------: |
+| [`LoadImageFromFile`](TODO) | Load from file path |
+| [`LoadAnnotations`](TODO) | Load and organize the annotations (bbox, etc.) |
+
+### Data preprocessing and enhancement
+
+Data preprocessing and augmentation usually involve transforming the image itself, such as cropping, padding, scaling, etc.
+
+| Class | Feature |
+| :------------------------------: | :----------------------------------------------------: |
+| [`Pad`](TODO) | Padding |
+| [`CenterCrop`](TODO) | Center crop |
+| [`Normalize`](TODO) | Image normalization |
+| [`Resize`](TODO) | Resize to the specified size or ratio |
+| [`RandomResize`](TODO) | Scale the image randomly within the specified range |
+| [`RandomMultiscaleResize`](TODO) | Scale the image to a random size from multiple options |
+| [`RandomGrayscale`](TODO) | Random grayscale |
+| [`RandomFlip`](TODO) | Random flip |
+| [`MultiScaleFlipAug`](TODO) | Support scaling and flipping during the testing |
+
+### Data formatting
+
+Data formatting operations are type conversions performed on the data.
+
+| Class | Feature |
+| :---------------------: | :------------------------------------------: |
+| [`ToTensor`](TODO) | Convert the specified data to `torch.Tensor` |
+| [`ImageToTensor`](TODO) | Convert the image to `torch.Tensor` |
+
+## Customize data transformation classes
+
+To implement a new data transformation class, you must inherit `BaseTransform` and implement the `transform` method. Here, we use a simple flip transform (`MyFlip`) as an example:
+
+```python
+import random
+import mmcv
+from mmcv.transforms import BaseTransform, TRANSFORMS
+
+@TRANSFORMS.register_module()
+class MyFlip(BaseTransform):
+ def __init__(self, direction: str):
+ super().__init__()
+ self.direction = direction
+
+ def transform(self, results: dict) -> dict:
+ img = results['img']
+ results['img'] = mmcv.imflip(img, direction=self.direction)
+ return results
+```
+
+Now, we can instantiate `MyFlip` as a callable object to handle our data dictionary.
+
+```python
+import numpy as np
+
+transform = MyFlip(direction='horizontal')
+data_dict = {'img': np.random.rand(224, 224, 3)}
+data_dict = transform(data_dict)
+processed_img = data_dict['img']
+```
+
+Alternatively, use `MyFlip` transform in the `pipeline` of the config file.
+
+```python
+pipeline = [
+ ...
+ dict(type='MyFlip', direction='horizontal'),
+ ...
+]
+```
+
+It should be noted that if you want to use it in the configuration file, you must ensure that the file where the `MyFlip` class is located can be imported at the runtime.
+
+## Transform wrapper
+
+Transform wrappers are a special class of data transformations. They do not operate on images, labels or other information in the data dictionary by themselves. Instead, they enhance the behavior of data transformations defined in them.
+
+### KeyMapper
+
+`KeyMapper` is used to map fields in the data dictionary. For example, image processing transforms usually get their values from the `"img"` field in the data dictionary. But sometimes we want these transforms to handle images in other fields in the data dictionary, such as the `"gt_img"` field.
+
+When used with registry and configuration file, the field map wrapper should be used as follows:
+
+```python
+pipeline = [
+ ...
+ dict(type='KeyMapper',
+ mapping={
+ 'img': 'gt_img', # map "gt_img" to "img"
+ 'mask': ..., # The "mask" field in the raw data is not used. That is, for wrapped data transformations, the "mask" field is not included in the data
+ },
+ auto_remap=True, # remap "img" back to "gt_img" after the transformation
+ transforms=[
+ # only need to specify "img" in `RandomFlip`
+ dict(type='RandomFlip'),
+ ])
+ ...
+]
+```
+
+With `KeyMapper`, we don't need to consider various possible input field names in the `transform` method when we implement the data transformation class. We only need to deal with the default fields.
+
+### RandomChoice and RandomApply
+
+`RandomChoice` is used to randomly select a data transformation pipeline from the given choices. With this wrapper, we can easily implement some data augmentation functions, such as AutoAugment.
+
+In configuration file, you can use `RandomChoice` as follows:
+
+```python
+pipeline = [
+ ...
+ dict(type='RandomChoice',
+ transforms=[
+ [
+ dict(type='Posterize', bits=4),
+ dict(type='Rotate', angle=30.)
+ ], # the first combo option
+ [
+ dict(type='Equalize'),
+ dict(type='Rotate', angle=30)
+ ], # the second combo option
+ ],
+ prob=[0.4, 0.6] # the prob of each combo
+ )
+ ...
+]
+```
+
+`RandomApply` is used to randomly perform a combination of data transformations with a specified probability. For example:
+
+```python
+pipeline = [
+ ...
+ dict(type='RandomApply',
+ transforms=[dict(type='Rotate', angle=30.)],
+ prob=0.3) # perform the transformation with prob as 0.3
+ ...
+]
+```
+
+### TransformBroadcaster
+
+Usually, a data transformation class only reads the target of an operation from one field. While we can also use `KeyMapper` to change the fields read, there is no way to apply transformations to the data of multiple fields at once. To achieve this, we need to use the multi-target extension wrapper `TransformBroadcaster`.
+
+`TransformBroadcaster` has two uses, one is to apply data transformation to multiple specified fields, and the other is to apply data transformation to a group of targets under a field.
+
+1. Apply to multiple fields
+
+ Suppose we need to apply a data transformation to images in two fields `"lq"` (low-quality) and `"gt"` (ground-truth).
+
+ ```python
+ pipeline = [
+ dict(type='TransformBroadcaster',
+ # apply to the "lq" and "gt" fields respectively, and set the "img" field to both
+ mapping={'img': ['lq', 'gt']},
+ # remap the "img" field back to the original field after the transformation
+ auto_remap=True,
+ # whether to share random variables in the transformation of each target
+ # more introduction will be referred in the following chapters (random variable sharing)
+ share_random_params=True,
+ transforms=[
+ # only need to manipulate the "img" field in the `RandomFlip` class
+ dict(type='RandomFlip'),
+ ])
+ ]
+ ```
+
+ In the `mapping` setting of the multi-target extension, we can also use `...` to ignore the specified original field. As shown in the following example, the wrapped `RandomCrop` will crop the image in the field `"img"` and update the size of the cropped image if the field `"img_shape"` exists. If we want to do the same random cropping for both image fields `"lq"` and `"gt"` at the same time but update the `"img_shape"` field only once, we can do it as in the example:
+
+ ```python
+ pipeline = [
+ dict(type='TransformBroadcaster',
+ mapping={
+ 'img': ['lq', 'gt'],
+ 'img_shape': ['img_shape', ...],
+ },
+ # remap the "img" and "img_shape" fields back to their original fields after the transformation
+ auto_remap=True,
+ # whether to share random variables in the transformation of each target
+ # more introduction will be referred in the following chapters (random variable sharing)
+ share_random_params=True,
+ transforms=[
+ # "img" and "img_shape" fields are manipulated in the `RandomCrop` class
+ # if "img_shape" is missing, only operate on "img"
+ dict(type='RandomCrop'),
+ ])
+ ]
+ ```
+
+2. A set of targets applied to a field
+
+ Suppose we need to apply a data transformation to the `"images"` field, which is a list of images.
+
+ ```python
+ pipeline = [
+ dict(type='TransformBroadcaster',
+ # map each image under the "images" field to the "img" field
+ mapping={'img': 'images'},
+ # remap the images under the "img" field back to the list in the "images" field after the transformation
+ auto_remap=True,
+ # whether to share random variables in the transformation of each target
+ share_random_params=True,
+ transforms=[
+ # in the `RandomFlip` transformation class, we only need to manipulate the "img" field
+ dict(type='RandomFlip'),
+ ])
+ ]
+ ```
+
+#### Decorator `cache_randomness`
+
+In `TransformBroadcaster`, we provide the `share_random_params` option to support sharing random states across multiple data transformations. For example, in a super-resolution task, we want to apply **the same** random transformations **simultaneously** to the low-resolution image and the original image. If we use this function in a custom data transformation class, we need to mark which random variables support sharing in the class. This can be achieved with the decorator `cache_randomness`.
+
+Taking `MyFlip` from the above example, we want to perform flipping randomly with a certain probability:
+
+```python
+from mmcv.transforms.utils import cache_randomness
+
+@TRANSFORMS.register_module()
+class MyRandomFlip(BaseTransform):
+ def __init__(self, prob: float, direction: str):
+ super().__init__()
+ self.prob = prob
+ self.direction = direction
+
+ @cache_randomness # label the output of the method as a shareable random variable
+ def do_flip(self):
+ flip = True if random.random() > self.prob else False
+ return flip
+
+ def transform(self, results: dict) -> dict:
+ img = results['img']
+ if self.do_flip():
+ results['img'] = mmcv.imflip(img, direction=self.direction)
+ return results
+```
+
+In the above example, we decorate the `do_flip` method with `cache_randomness`, marking the method return value `flip` as a random variable that supports sharing. Therefore, in the transformation of `TransformBroadcaster` to multiple targets, the value of this variable will remain the same.
+
+#### Decorator `avoid_cache_randomness`
+
+In some cases, we cannot separate the process of generating random variables in data transformation into a class method. For example, modules from third-party libraries used in data transformation encapsulate the relevant parts of random variables inside, making them impossible to be extracted as class methods for data transformation. Such data transformations cannot support shared random variables through the decorator `cache_randomness` annotation, and thus cannot share random variables during multi-objective expansion.
+
+To avoid misuse of such data transformations in multi-object extensions, we provide another decorator, `avoid_cache_randomness`, to mark such data transformations:
+
+```python
+from mmcv.transforms.utils import avoid_cache_randomness
+
+@TRANSFORMS.register_module()
+@avoid_cache_randomness
+class MyRandomTransform(BaseTransform):
+
+ def transform(self, results: dict) -> dict:
+ ...
+```
+
+Data transformation classes marked with `avoid_cache_randomness` will throw an exception when their instance is wrapped by `TransformBroadcaster` and the parameter `share_random_params` is set to True. This reminds the user not to use it in this way.
+
+There are a few things to keep in mind when using `avoid_cache_randomness`:
+
+1. `avoid_cache_randomness` is only used to decorate data transformation classes (subclasses of `BaseTransfrom`) and cannot be used to decorate other general classes, class methods, or functions
+2. When a data transformation decorated with `avoid_cache_randomness` is used as a base class, its subclasses **will not inherit** its feature. If the subclass is still unable to share random variables, `avoid_cache_randomness` should be used again.
+3. A data transformation needs to be modified with `avoid_cache_randomness` only when a data transformation is random and cannot share its random parameters. Data transformations without randomness require no decoration
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/en/understand_mmcv/ops.md b/cv/distiller/CWD/pytorch/mmcv/docs/en/understand_mmcv/ops.md
new file mode 100644
index 0000000000000000000000000000000000000000..5579cd7757fa344519e69c7fb1091de6fe32fdcc
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/en/understand_mmcv/ops.md
@@ -0,0 +1,63 @@
+## ops
+
+We implement common ops used in detection, segmentation, etc.
+
+| Device | CPU | CUDA | MLU | MPS | Ascend |
+| ---------------------------- | --- | ---- | --- | --- | ------ |
+| ActiveRotatedFilter | √ | √ | | | |
+| AssignScoreWithK | | √ | | | |
+| BallQuery | | √ | | | |
+| BBoxOverlaps | | √ | √ | √ | |
+| BorderAlign | | √ | | | |
+| BoxIouRotated | √ | √ | | | |
+| BoxIouQuadri | √ | √ | | | |
+| CARAFE | | √ | √ | | |
+| ChamferDistance | | √ | | | |
+| CrissCrossAttention | | √ | | | |
+| ContourExpand | √ | | | | |
+| ConvexIoU | | √ | | | |
+| CornerPool | | √ | | | |
+| Correlation | | √ | | | |
+| Deformable Convolution v1/v2 | √ | √ | | | √ |
+| Deformable RoIPool | | √ | √ | | √ |
+| DiffIoURotated | | √ | | | |
+| DynamicScatter | | √ | | | |
+| FurthestPointSample | | √ | | | |
+| FurthestPointSampleWithDist | | √ | | | |
+| FusedBiasLeakyrelu | | √ | | | √ |
+| GatherPoints | | √ | | | |
+| GroupPoints | | √ | | | |
+| Iou3d | | √ | √ | | |
+| KNN | | √ | | | |
+| MaskedConv | | √ | √ | | √ |
+| MergeCells | | √ | | | |
+| MinAreaPolygon | | √ | | | |
+| ModulatedDeformConv2d | √ | √ | | | √ |
+| MultiScaleDeformableAttn | | √ | √ | | |
+| NMS | √ | √ | √ | | √ |
+| NMSRotated | √ | √ | | | |
+| NMSQuadri | √ | √ | | | |
+| PixelGroup | √ | | | | |
+| PointsInBoxes | √ | √ | | | |
+| PointsInPolygons | | √ | | | |
+| PSAMask | √ | √ | √ | | √ |
+| RotatedFeatureAlign | √ | √ | | | |
+| RoIPointPool3d | | √ | √ | | |
+| RoIPool | | √ | √ | | √ |
+| RoIAlignRotated | √ | √ | √ | | |
+| RiRoIAlignRotated | | √ | | | |
+| RoIAlign | √ | √ | √ | | |
+| RoIAwarePool3d | | √ | √ | | |
+| SAConv2d | | √ | | | |
+| SigmoidFocalLoss | | √ | √ | | √ |
+| SoftmaxFocalLoss | | √ | | | √ |
+| SoftNMS | | √ | | | |
+| Sparse Convolution | | √ | | | |
+| Synchronized BatchNorm | | √ | | | |
+| ThreeInterpolate | | √ | | | |
+| ThreeNN | | √ | √ | | |
+| TINShift | | √ | √ | | |
+| UpFirDn2d | | √ | | | |
+| Voxelization | √ | √ | | | |
+| PrRoIPool | | √ | | | |
+| BezierAlign | √ | √ | | | |
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/en/understand_mmcv/visualization.md b/cv/distiller/CWD/pytorch/mmcv/docs/en/understand_mmcv/visualization.md
new file mode 100644
index 0000000000000000000000000000000000000000..968e350589aafdf79c32593a6b5968329d5afa2a
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/en/understand_mmcv/visualization.md
@@ -0,0 +1,24 @@
+## Visualization
+
+`mmcv` can show images and annotations (currently supported types include bounding boxes).
+
+```python
+# show an image file
+mmcv.imshow('a.jpg')
+
+# show a loaded image
+img = np.random.rand(100, 100, 3)
+mmcv.imshow(img)
+
+# show image with bounding boxes
+img = np.random.rand(100, 100, 3)
+bboxes = np.array([[0, 0, 50, 50], [20, 20, 60, 60]])
+mmcv.imshow_bboxes(img, bboxes)
+```
+
+`mmcv` can also visualize special images such as optical flows.
+
+```python
+flow = mmcv.flowread('test.flo')
+mmcv.flowshow(flow)
+```
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/Makefile b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..51285967a7d9722c5bdee4f6a81c154a56aa0846
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/Makefile
@@ -0,0 +1,19 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line.
+SPHINXOPTS =
+SPHINXBUILD = sphinx-build
+SOURCEDIR = .
+BUILDDIR = _build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/_static/css/readthedocs.css b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/_static/css/readthedocs.css
new file mode 100644
index 0000000000000000000000000000000000000000..9e3a567d5f78aedb606600bb3111034a1003b362
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/_static/css/readthedocs.css
@@ -0,0 +1,10 @@
+.header-logo {
+ background-image: url("../image/mmcv-logo.png");
+ background-size: 85px 40px;
+ height: 40px;
+ width: 85px;
+}
+
+table.colwidths-auto td {
+ width: 50%
+}
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/_static/image/mmcv-logo.png b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/_static/image/mmcv-logo.png
new file mode 100644
index 0000000000000000000000000000000000000000..bcc5759f8fe3bc7d191d411c38a9e1d3c1c27a84
Binary files /dev/null and b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/_static/image/mmcv-logo.png differ
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/_static/version.json b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/_static/version.json
new file mode 100644
index 0000000000000000000000000000000000000000..7ee4965d36ed96f63f484137921d156d19cc40da
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/_static/version.json
@@ -0,0 +1,575 @@
+{
+ "Linux": [
+ {
+ "cuda": "11.7",
+ "torch": "1.13.x",
+ "mmcv": [
+ "2.0.0rc3"
+ ]
+ },
+ {
+ "cuda": "11.6",
+ "torch": "1.13.x",
+ "mmcv": [
+ "2.0.0rc3"
+ ]
+ },
+ {
+ "cuda": "11.6",
+ "torch": "1.12.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "11.5",
+ "torch": "1.11.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "11.3",
+ "torch": "1.12.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "11.3",
+ "torch": "1.11.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "11.3",
+ "torch": "1.10.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "11.1",
+ "torch": "1.10.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "11.1",
+ "torch": "1.9.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "11.1",
+ "torch": "1.8.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "11.0",
+ "torch": "1.7.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "10.2",
+ "torch": "1.12.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "10.2",
+ "torch": "1.11.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "10.2",
+ "torch": "1.10.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "10.2",
+ "torch": "1.9.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "10.2",
+ "torch": "1.8.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "10.2",
+ "torch": "1.7.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "10.2",
+ "torch": "1.6.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "10.1",
+ "torch": "1.8.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "10.1",
+ "torch": "1.7.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "10.1",
+ "torch": "1.6.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "9.2",
+ "torch": "1.7.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "9.2",
+ "torch": "1.6.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.13.x",
+ "mmcv": [
+ "2.0.0rc3"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.12.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.11.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.10.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.9.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.8.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.7.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.6.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ }
+ ],
+ "Windows": [
+ {
+ "cuda": "11.7",
+ "torch": "1.13.x",
+ "mmcv": [
+ "2.0.0rc3"
+ ]
+ },
+ {
+ "cuda": "11.6",
+ "torch": "1.13.x",
+ "mmcv": [
+ "2.0.0rc3"
+ ]
+ },
+ {
+ "cuda": "11.6",
+ "torch": "1.12.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "11.5",
+ "torch": "1.11.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "11.3",
+ "torch": "1.12.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "11.3",
+ "torch": "1.11.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "11.3",
+ "torch": "1.10.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "11.1",
+ "torch": "1.10.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "11.1",
+ "torch": "1.9.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "11.1",
+ "torch": "1.8.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "10.2",
+ "torch": "1.10.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "10.2",
+ "torch": "1.9.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "10.2",
+ "torch": "1.8.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "10.2",
+ "torch": "1.7.x",
+ "mmcv": [
+ "2.0.0rc3"
+ ]
+ },
+ {
+ "cuda": "10.2",
+ "torch": "1.6.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "10.1",
+ "torch": "1.8.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "10.1",
+ "torch": "1.7.x",
+ "mmcv": [
+ "2.0.0rc3"
+ ]
+ },
+ {
+ "cuda": "10.1",
+ "torch": "1.6.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.13.x",
+ "mmcv": [
+ "2.0.0rc3"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.12.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.11.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.10.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.9.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.8.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.7.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.6.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2",
+ "2.0.0rc1"
+ ]
+ }
+ ],
+ "macOS": [
+ {
+ "cuda": "cpu",
+ "torch": "1.13.x",
+ "mmcv": [
+ "2.0.0rc3"
+ ]
+ },
+ {
+ "cuda": "mps",
+ "torch": "1.13.x",
+ "mmcv": [
+ "2.0.0rc3"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.12.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.11.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.10.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.9.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.8.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.7.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2"
+ ]
+ },
+ {
+ "cuda": "cpu",
+ "torch": "1.6.x",
+ "mmcv": [
+ "2.0.0rc3",
+ "2.0.0rc2"
+ ]
+ }
+ ]
+}
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/_templates/classtemplate.rst b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/_templates/classtemplate.rst
new file mode 100644
index 0000000000000000000000000000000000000000..4f74842394ec9807fb1ae2d8f05a8a57e9a2e24c
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/_templates/classtemplate.rst
@@ -0,0 +1,14 @@
+.. role:: hidden
+ :class: hidden-section
+.. currentmodule:: {{ module }}
+
+
+{{ name | underline}}
+
+.. autoclass:: {{ name }}
+ :members:
+
+
+..
+ autogenerated from source/_templates/classtemplate.rst
+ note it does not have :inherited-members:
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/arraymisc.rst b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/arraymisc.rst
new file mode 100644
index 0000000000000000000000000000000000000000..28975eb76e94994c50d2fe52b8f34c7ce533e788
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/arraymisc.rst
@@ -0,0 +1,19 @@
+.. role:: hidden
+ :class: hidden-section
+
+mmcv.arraymisc
+===================================
+
+.. contents:: mmcv.arraymisc
+ :depth: 2
+ :local:
+ :backlinks: top
+
+.. currentmodule:: mmcv.arraymisc
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+
+ quantize
+ dequantize
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/cnn.rst b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/cnn.rst
new file mode 100644
index 0000000000000000000000000000000000000000..5cbcb191e9e4feb7a76e9d154411fd899a48999e
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/cnn.rst
@@ -0,0 +1,70 @@
+.. role:: hidden
+ :class: hidden-section
+
+mmcv.cnn
+===================================
+
+.. contents:: mmcv.cnn
+ :depth: 2
+ :local:
+ :backlinks: top
+
+.. currentmodule:: mmcv.cnn
+
+Module
+----------------
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+ :template: classtemplate.rst
+
+ ContextBlock
+ Conv2d
+ Conv3d
+ ConvAWS2d
+ ConvModule
+ ConvTranspose2d
+ ConvTranspose3d
+ ConvWS2d
+ DepthwiseSeparableConvModule
+ GeneralizedAttention
+ HSigmoid
+ HSwish
+ LayerScale
+ Linear
+ MaxPool2d
+ MaxPool3d
+ NonLocal1d
+ NonLocal2d
+ NonLocal3d
+ Scale
+ Swish
+
+Build Function
+----------------
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+
+ build_activation_layer
+ build_conv_layer
+ build_norm_layer
+ build_padding_layer
+ build_plugin_layer
+ build_upsample_layer
+
+Miscellaneous
+----------------
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+
+ fuse_conv_bn
+ conv_ws_2d
+ is_norm
+ make_res_layer
+ make_vgg_layer
+ get_model_complexity_info
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/image.rst b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/image.rst
new file mode 100644
index 0000000000000000000000000000000000000000..3b93484952cd0c45b9d103088b0677f93fe5615d
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/image.rst
@@ -0,0 +1,100 @@
+.. role:: hidden
+ :class: hidden-section
+
+mmcv.image
+===================================
+
+.. contents:: mmcv.image
+ :depth: 2
+ :local:
+ :backlinks: top
+
+.. currentmodule:: mmcv.image
+
+IO
+----------------
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+
+ imfrombytes
+ imread
+ imwrite
+ use_backend
+
+Color Space
+----------------
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+
+ bgr2gray
+ bgr2hls
+ bgr2hsv
+ bgr2rgb
+ bgr2ycbcr
+ gray2bgr
+ gray2rgb
+ hls2bgr
+ hsv2bgr
+ imconvert
+ rgb2bgr
+ rgb2gray
+ rgb2ycbcr
+ ycbcr2bgr
+ ycbcr2rgb
+
+Geometric
+----------------
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+
+ cutout
+ imcrop
+ imflip
+ impad
+ impad_to_multiple
+ imrescale
+ imresize
+ imresize_like
+ imresize_to_multiple
+ imrotate
+ imshear
+ imtranslate
+ rescale_size
+
+Photometric
+----------------
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+
+ adjust_brightness
+ adjust_color
+ adjust_contrast
+ adjust_hue
+ adjust_lighting
+ adjust_sharpness
+ auto_contrast
+ clahe
+ imdenormalize
+ imequalize
+ iminvert
+ imnormalize
+ lut_transform
+ posterize
+ solarize
+
+Miscellaneous
+----------------
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+
+ tensor2imgs
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/ops.rst b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/ops.rst
new file mode 100644
index 0000000000000000000000000000000000000000..b0290457bfa0c08f14d7fe346efccb33f388bdae
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/ops.rst
@@ -0,0 +1,135 @@
+.. role:: hidden
+ :class: hidden-section
+
+mmcv.ops
+===================================
+
+.. contents:: mmcv.ops
+ :depth: 2
+ :local:
+ :backlinks: top
+
+.. currentmodule:: mmcv.ops
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+ :template: classtemplate.rst
+
+ BorderAlign
+ CARAFE
+ CARAFENaive
+ CARAFEPack
+ Conv2d
+ ConvTranspose2d
+ CornerPool
+ Correlation
+ CrissCrossAttention
+ DeformConv2d
+ DeformConv2dPack
+ DeformRoIPool
+ DeformRoIPoolPack
+ DynamicScatter
+ FusedBiasLeakyReLU
+ GroupAll
+ Linear
+ MaskedConv2d
+ MaxPool2d
+ ModulatedDeformConv2d
+ ModulatedDeformConv2dPack
+ ModulatedDeformRoIPoolPack
+ MultiScaleDeformableAttention
+ PSAMask
+ PointsSampler
+ PrRoIPool
+ QueryAndGroup
+ RiRoIAlignRotated
+ RoIAlign
+ RoIAlignRotated
+ RoIAwarePool3d
+ RoIPointPool3d
+ RoIPool
+ SAConv2d
+ SigmoidFocalLoss
+ SimpleRoIAlign
+ SoftmaxFocalLoss
+ SparseConv2d
+ SparseConv3d
+ SparseConvTensor
+ SparseConvTranspose2d
+ SparseConvTranspose3d
+ SparseInverseConv2d
+ SparseInverseConv3d
+ SparseMaxPool2d
+ SparseMaxPool3d
+ SparseModule
+ SparseSequential
+ SubMConv2d
+ SubMConv3d
+ SyncBatchNorm
+ TINShift
+ Voxelization
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+
+ active_rotated_filter
+ assign_score_withk
+ ball_query
+ batched_nms
+ bbox_overlaps
+ border_align
+ box_iou_rotated
+ boxes_iou3d
+ boxes_iou_bev
+ boxes_overlap_bev
+ carafe
+ carafe_naive
+ chamfer_distance
+ contour_expand
+ convex_giou
+ convex_iou
+ deform_conv2d
+ deform_roi_pool
+ diff_iou_rotated_2d
+ diff_iou_rotated_3d
+ dynamic_scatter
+ furthest_point_sample
+ furthest_point_sample_with_dist
+ fused_bias_leakyrelu
+ gather_points
+ grouping_operation
+ knn
+ masked_conv2d
+ min_area_polygons
+ modulated_deform_conv2d
+ nms
+ nms3d
+ nms3d_normal
+ nms_bev
+ nms_match
+ nms_normal_bev
+ nms_rotated
+ pixel_group
+ point_sample
+ points_in_boxes_all
+ points_in_boxes_cpu
+ points_in_boxes_part
+ points_in_polygons
+ prroi_pool
+ rel_roi_point_to_rel_img_point
+ riroi_align_rotated
+ roi_align
+ roi_align_rotated
+ roi_pool
+ rotated_feature_align
+ scatter_nd
+ sigmoid_focal_loss
+ soft_nms
+ softmax_focal_loss
+ three_interpolate
+ three_nn
+ tin_shift
+ upfirdn2d
+ voxelization
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/transforms.rst b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/transforms.rst
new file mode 100644
index 0000000000000000000000000000000000000000..56463b304e39734ad55d27a2f5ab54ad529de7ed
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/transforms.rst
@@ -0,0 +1,57 @@
+.. role:: hidden
+ :class: hidden-section
+
+mmcv.transforms
+===================================
+
+.. currentmodule:: mmcv.transforms
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+ :template: classtemplate.rst
+
+ BaseTransform
+
+Loading
+----------------
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+ :template: classtemplate.rst
+
+ LoadAnnotations
+ LoadImageFromFile
+
+Processing
+----------------
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+ :template: classtemplate.rst
+
+ CenterCrop
+ MultiScaleFlipAug
+ Normalize
+ Pad
+ RandomChoiceResize
+ RandomFlip
+ RandomGrayscale
+ RandomResize
+ Resize
+
+Wrapper
+----------------
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+ :template: classtemplate.rst
+
+ Compose
+ KeyMapper
+ RandomApply
+ RandomChoice
+ TransformBroadcaster
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/utils.rst b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/utils.rst
new file mode 100644
index 0000000000000000000000000000000000000000..f2ff4c2a3872bc9ae0c2942debac5e5b523bd071
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/utils.rst
@@ -0,0 +1,23 @@
+.. role:: hidden
+ :class: hidden-section
+
+mmcv.utils
+===================================
+
+.. contents:: mmcv.utils
+ :depth: 2
+ :local:
+ :backlinks: top
+
+.. currentmodule:: mmcv.utils
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+
+ IS_CUDA_AVAILABLE
+ IS_MLU_AVAILABLE
+ IS_MPS_AVAILABLE
+ collect_env
+ jit
+ skip_no_elena
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/video.rst b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/video.rst
new file mode 100644
index 0000000000000000000000000000000000000000..a6ebca0eb73afcf3f3f11aae8520e2782a310f13
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/video.rst
@@ -0,0 +1,56 @@
+.. role:: hidden
+ :class: hidden-section
+
+mmcv.video
+===================================
+
+.. contents:: mmcv.video
+ :depth: 2
+ :local:
+ :backlinks: top
+
+.. currentmodule:: mmcv.video
+
+IO
+----------------
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+ :template: classtemplate.rst
+
+ VideoReader
+ Cache
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+
+ frames2video
+
+Optical Flow
+----------------
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+
+ dequantize_flow
+ flow_from_bytes
+ flow_warp
+ flowread
+ flowwrite
+ quantize_flow
+ sparse_flow_from_bytes
+
+Video Processing
+----------------
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+
+ concat_video
+ convert_video
+ cut_video
+ resize_video
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/visualization.rst b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/visualization.rst
new file mode 100644
index 0000000000000000000000000000000000000000..8f43ef27a441dcd9001a352cf18e97f8e615676d
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/api/visualization.rst
@@ -0,0 +1,50 @@
+.. role:: hidden
+ :class: hidden-section
+
+mmcv.visualization
+===================================
+
+.. contents:: mmcv.visualization
+ :depth: 2
+ :local:
+ :backlinks: top
+
+.. currentmodule:: mmcv.visualization
+
+Color
+----------------
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+ :template: classtemplate.rst
+
+ Color
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+
+ color_val
+
+Image
+----------------
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+
+ imshow
+ imshow_bboxes
+ imshow_det_bboxes
+
+Optical Flow
+----------------
+
+.. autosummary::
+ :toctree: generated
+ :nosignatures:
+
+ flow2rgb
+ flowshow
+ make_color_wheel
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/community/code_style.md b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/community/code_style.md
new file mode 100644
index 0000000000000000000000000000000000000000..8ddb87c2391e07b848aa073287cc2a230da8c3ec
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/community/code_style.md
@@ -0,0 +1,609 @@
+## 代码规范
+
+### 代码规范标准
+
+#### PEP 8 —— Python 官方代码规范
+
+[Python 官方的代码风格指南](https://www.python.org/dev/peps/pep-0008/),包含了以下几个方面的内容:
+
+- 代码布局,介绍了 Python 中空行、断行以及导入相关的代码风格规范。比如一个常见的问题:当我的代码较长,无法在一行写下时,何处可以断行?
+
+- 表达式,介绍了 Python 中表达式空格相关的一些风格规范。
+
+- 尾随逗号相关的规范。当列表较长,无法一行写下而写成如下逐行列表时,推荐在末项后加逗号,从而便于追加选项、版本控制等。
+
+ ```python
+ # Correct:
+ FILES = ['setup.cfg', 'tox.ini']
+ # Correct:
+ FILES = [
+ 'setup.cfg',
+ 'tox.ini',
+ ]
+ # Wrong:
+ FILES = ['setup.cfg', 'tox.ini',]
+ # Wrong:
+ FILES = [
+ 'setup.cfg',
+ 'tox.ini'
+ ]
+ ```
+
+- 命名相关规范、注释相关规范、类型注解相关规范,我们将在后续章节中做详细介绍。
+
+ "A style guide is about consistency. Consistency with this style guide is important. Consistency within a project is more important. Consistency within one module or function is the most important." PEP 8 -- Style Guide for Python Code
+
+:::{note}
+PEP 8 的代码规范并不是绝对的,项目内的一致性要优先于 PEP 8 的规范。OpenMMLab 各个项目都在 setup.cfg 设定了一些代码规范的设置,请遵照这些设置。一个例子是在 PEP 8 中有如下一个例子:
+
+```python
+# Correct:
+hypot2 = x*x + y*y
+# Wrong:
+hypot2 = x * x + y * y
+```
+
+这一规范是为了指示不同优先级,但 OpenMMLab 的设置中通常没有启用 yapf 的 `ARITHMETIC_PRECEDENCE_INDICATION` 选项,因而格式规范工具不会按照推荐样式格式化,以设置为准。
+:::
+
+#### Google 开源项目风格指南
+
+[Google 使用的编程风格指南](https://google.github.io/styleguide/pyguide.html),包括了 Python 相关的章节。相较于 PEP 8,该指南提供了更为详尽的代码指南。该指南包括了语言规范和风格规范两个部分。
+
+其中,语言规范对 Python 中很多语言特性进行了优缺点的分析,并给出了使用指导意见,如异常、Lambda 表达式、列表推导式、metaclass 等。
+
+风格规范的内容与 PEP 8 较为接近,大部分约定建立在 PEP 8 的基础上,也有一些更为详细的约定,如函数长度、TODO 注释、文件与 socket 对象的访问等。
+
+推荐将该指南作为参考进行开发,但不必严格遵照,一来该指南存在一些 Python 2 兼容需求,例如指南中要求所有无基类的类应当显式地继承 Object, 而在仅使用 Python 3 的环境中,这一要求是不必要的,依本项目中的惯例即可。二来 OpenMMLab 的项目作为框架级的开源软件,不必对一些高级技巧过于避讳,尤其是 MMCV。但尝试使用这些技巧前应当认真考虑是否真的有必要,并寻求其他开发人员的广泛评估。
+
+另外需要注意的一处规范是关于包的导入,在该指南中,要求导入本地包时必须使用路径全称,且导入的每一个模块都应当单独成行,通常这是不必要的,而且也不符合目前项目的开发惯例,此处进行如下约定:
+
+```python
+# Correct
+from mmcv.cnn.bricks import (Conv2d, build_norm_layer, DropPath, MaxPool2d,
+ Linear)
+from ..utils import ext_loader
+
+# Wrong
+from mmcv.cnn.bricks import Conv2d, build_norm_layer, DropPath, MaxPool2d, \
+ Linear # 使用括号进行连接,而不是反斜杠
+from ...utils import is_str # 最多向上回溯一层,过多的回溯容易导致结构混乱
+```
+
+OpenMMLab 项目使用 pre-commit 工具自动格式化代码,详情见[贡献代码](./contributing.md#代码风格)。
+
+### 命名规范
+
+#### 命名规范的重要性
+
+优秀的命名是良好代码可读的基础。基础的命名规范对各类变量的命名做了要求,使读者可以方便地根据代码名了解变量是一个类 / 局部变量 / 全局变量等。而优秀的命名则需要代码作者对于变量的功能有清晰的认识,以及良好的表达能力,从而使读者根据名称就能了解其含义,甚至帮助了解该段代码的功能。
+
+#### 基础命名规范
+
+| 类型 | 公有 | 私有 |
+| --------------- | ---------------- | ------------------ |
+| 模块 | lower_with_under | \_lower_with_under |
+| 包 | lower_with_under | |
+| 类 | CapWords | \_CapWords |
+| 异常 | CapWordsError | |
+| 函数(方法) | lower_with_under | \_lower_with_under |
+| 函数 / 方法参数 | lower_with_under | |
+| 全局 / 类内常量 | CAPS_WITH_UNDER | \_CAPS_WITH_UNDER |
+| 全局 / 类内变量 | lower_with_under | \_lower_with_under |
+| 变量 | lower_with_under | \_lower_with_under |
+| 局部变量 | lower_with_under | |
+
+注意:
+
+- 尽量避免变量名与保留字冲突,特殊情况下如不可避免,可使用一个后置下划线,如 class\_
+- 尽量不要使用过于简单的命名,除了约定俗成的循环变量 i,文件变量 f,错误变量 e 等。
+- 不会被用到的变量可以命名为 \_,逻辑检查器会将其忽略。
+
+#### 命名技巧
+
+良好的变量命名需要保证三点:
+
+1. 含义准确,没有歧义
+2. 长短适中
+3. 前后统一
+
+```python
+# Wrong
+class Masks(metaclass=ABCMeta): # 命名无法表现基类;Instance or Semantic?
+ pass
+
+# Correct
+class BaseInstanceMasks(metaclass=ABCMeta):
+ pass
+
+# Wrong,不同地方含义相同的变量尽量用统一的命名
+def __init__(self, inplanes, planes):
+ pass
+
+def __init__(self, in_channels, out_channels):
+ pass
+```
+
+常见的函数命名方法:
+
+- 动宾命名法:crop_img, init_weights
+- 动宾倒置命名法:imread, bbox_flip
+
+注意函数命名与参数的顺序,保证主语在前,符合语言习惯:
+
+- check_keys_exist(key, container)
+- check_keys_contain(container, key)
+
+注意避免非常规或统一约定的缩写,如 nb -> num_blocks,in_nc -> in_channels
+
+### docstring 规范
+
+#### 为什么要写 docstring
+
+docstring 是对一个类、一个函数功能与 API 接口的详细描述,有两个功能,一是帮助其他开发者了解代码功能,方便 debug 和复用代码;二是在 Readthedocs 文档中自动生成相关的 API reference 文档,帮助不了解源代码的社区用户使用相关功能。
+
+#### 如何写 docstring
+
+与注释不同,一份规范的 docstring 有着严格的格式要求,以便于 Python 解释器以及 sphinx 进行文档解析,详细的 docstring 约定参见 [PEP 257](https://www.python.org/dev/peps/pep-0257/)。此处以例子的形式介绍各种文档的标准格式,参考格式为 [Google 风格](https://zh-google-styleguide.readthedocs.io/en/latest/google-python-styleguide/python_style_rules/#comments)。
+
+1. 模块文档
+
+ 代码风格规范推荐为每一个模块(即 Python 文件)编写一个 docstring,但目前 OpenMMLab 项目大部分没有此类 docstring,因此不做硬性要求。
+
+ ```python
+ """A one line summary of the module or program, terminated by a period.
+
+ Leave one blank line. The rest of this docstring should contain an
+ overall description of the module or program. Optionally, it may also
+ contain a brief description of exported classes and functions and/or usage
+ examples.
+
+ Typical usage example:
+
+ foo = ClassFoo()
+ bar = foo.FunctionBar()
+ """
+ ```
+
+2. 类文档
+
+ 类文档是我们最常需要编写的,此处,按照 OpenMMLab 的惯例,我们使用了与 Google 风格不同的写法。如下例所示,文档中没有使用 Attributes 描述类属性,而是使用 Args 描述 __init__ 函数的参数。
+
+ 在 Args 中,遵照 `parameter (type): Description.` 的格式,描述每一个参数类型和功能。其中,多种类型可使用 `(float or str)` 的写法,可以为 None 的参数可以写为 `(int, optional)`。
+
+ ```python
+ class BaseRunner(metaclass=ABCMeta):
+ """The base class of Runner, a training helper for PyTorch.
+
+ All subclasses should implement the following APIs:
+
+ - ``run()``
+ - ``train()``
+ - ``val()``
+ - ``save_checkpoint()``
+
+ Args:
+ model (:obj:`torch.nn.Module`): The model to be run.
+ batch_processor (callable, optional): A callable method that process
+ a data batch. The interface of this method should be
+ ``batch_processor(model, data, train_mode) -> dict``.
+ Defaults to None.
+ optimizer (dict or :obj:`torch.optim.Optimizer`, optional): It can be
+ either an optimizer (in most cases) or a dict of optimizers
+ (in models that requires more than one optimizer, e.g., GAN).
+ Defaults to None.
+ work_dir (str, optional): The working directory to save checkpoints
+ and logs. Defaults to None.
+ logger (:obj:`logging.Logger`): Logger used during training.
+ Defaults to None. (The default value is just for backward
+ compatibility)
+ meta (dict, optional): A dict records some import information such as
+ environment info and seed, which will be logged in logger hook.
+ Defaults to None.
+ max_epochs (int, optional): Total training epochs. Defaults to None.
+ max_iters (int, optional): Total training iterations. Defaults to None.
+ """
+
+ def __init__(self,
+ model,
+ batch_processor=None,
+ optimizer=None,
+ work_dir=None,
+ logger=None,
+ meta=None,
+ max_iters=None,
+ max_epochs=None):
+ ...
+ ```
+
+ 另外,在一些算法实现的主体类中,建议加入原论文的链接;如果参考了其他开源代码的实现,则应加入 modified from,而如果是直接复制了其他代码库的实现,则应加入 copied from ,并注意源码的 License。如有必要,也可以通过 .. math:: 来加入数学公式
+
+ ```python
+ # 参考实现
+ # This func is modified from `detectron2
+ # `_.
+
+ # 复制代码
+ # This code was copied from the `ubelt
+ # library`_.
+
+ # 引用论文 & 添加公式
+ class LabelSmoothLoss(nn.Module):
+ r"""Initializer for the label smoothed cross entropy loss.
+
+ Refers to `Rethinking the Inception Architecture for Computer Vision
+ `_.
+
+ This decreases gap between output scores and encourages generalization.
+ Labels provided to forward can be one-hot like vectors (NxC) or class
+ indices (Nx1).
+ And this accepts linear combination of one-hot like labels from mixup or
+ cutmix except multi-label task.
+
+ Args:
+ label_smooth_val (float): The degree of label smoothing.
+ num_classes (int, optional): Number of classes. Defaults to None.
+ mode (str): Refers to notes, Options are "original", "classy_vision",
+ "multi_label". Defaults to "classy_vision".
+ reduction (str): The method used to reduce the loss.
+ Options are "none", "mean" and "sum". Defaults to 'mean'.
+ loss_weight (float): Weight of the loss. Defaults to 1.0.
+
+ Note:
+ if the ``mode`` is "original", this will use the same label smooth
+ method as the original paper as:
+
+ .. math::
+ (1-\epsilon)\delta_{k, y} + \frac{\epsilon}{K}
+
+ where :math:`\epsilon` is the ``label_smooth_val``, :math:`K` is
+ the ``num_classes`` and :math:`\delta_{k,y}` is Dirac delta,
+ which equals 1 for k=y and 0 otherwise.
+
+ if the ``mode`` is "classy_vision", this will use the same label
+ smooth method as the `facebookresearch/ClassyVision
+ `_ repo as:
+
+ .. math::
+ \frac{\delta_{k, y} + \epsilon/K}{1+\epsilon}
+
+ if the ``mode`` is "multi_label", this will accept labels from
+ multi-label task and smoothing them as:
+
+ .. math::
+ (1-2\epsilon)\delta_{k, y} + \epsilon
+ ```
+
+```{note}
+注意 \`\`here\`\`、\`here\`、"here" 三种引号功能是不同。
+
+在 reStructured 语法中,\`\`here\`\` 表示一段代码;\`here\` 表示斜体;"here" 无特殊含义,一般可用来表示字符串。其中 \`here\` 的用法与 Markdown 中不同,需要多加留意。
+另外还有 :obj:\`type\` 这种更规范的表示类的写法,但鉴于长度,不做特别要求,一般仅用于表示非常用类型。
+```
+
+3. 方法(函数)文档
+
+ 函数文档与类文档的结构基本一致,但需要加入返回值文档。对于较为复杂的函数和类,可以使用 Examples 字段加入示例;如果需要对参数加入一些较长的备注,可以加入 Note 字段进行说明。
+
+ 对于使用较为复杂的类或函数,比起看大段大段的说明文字和参数文档,添加合适的示例更能帮助用户迅速了解其用法。需要注意的是,这些示例最好是能够直接在 Python 交互式环境中运行的,并给出一些相对应的结果。如果存在多个示例,可以使用注释简单说明每段示例,也能起到分隔作用。
+
+ ```python
+ def import_modules_from_strings(imports, allow_failed_imports=False):
+ """Import modules from the given list of strings.
+
+ Args:
+ imports (list | str | None): The given module names to be imported.
+ allow_failed_imports (bool): If True, the failed imports will return
+ None. Otherwise, an ImportError is raise. Defaults to False.
+
+ Returns:
+ List[module] | module | None: The imported modules.
+ All these three lines in docstring will be compiled into the same
+ line in readthedocs.
+
+ Examples:
+ >>> osp, sys = import_modules_from_strings(
+ ... ['os.path', 'sys'])
+ >>> import os.path as osp_
+ >>> import sys as sys_
+ >>> assert osp == osp_
+ >>> assert sys == sys_
+ """
+ ...
+ ```
+
+ 如果函数接口在某个版本发生了变化,需要在 docstring 中加入相关的说明,必要时添加 Note 或者 Warning 进行说明,例如:
+
+ ```python
+ class CheckpointHook(Hook):
+ """Save checkpoints periodically.
+
+ Args:
+ out_dir (str, optional): The root directory to save checkpoints. If
+ not specified, ``runner.work_dir`` will be used by default. If
+ specified, the ``out_dir`` will be the concatenation of
+ ``out_dir`` and the last level directory of ``runner.work_dir``.
+ Defaults to None. `Changed in version 1.3.15.`
+ file_client_args (dict, optional): Arguments to instantiate a
+ FileClient. See :class:`mmcv.fileio.FileClient` for details.
+ Defaults to None. `New in version 1.3.15.`
+
+ Warning:
+ Before v1.3.15, the ``out_dir`` argument indicates the path where the
+ checkpoint is stored. However, in v1.3.15 and later, ``out_dir``
+ indicates the root directory and the final path to save checkpoint is
+ the concatenation of out_dir and the last level directory of
+ ``runner.work_dir``. Suppose the value of ``out_dir`` is
+ "/path/of/A" and the value of ``runner.work_dir`` is "/path/of/B",
+ then the final path will be "/path/of/A/B".
+ ```
+
+ 如果参数或返回值里带有需要展开描述字段的 dict,则应该采用如下格式:
+
+ ```python
+ def func(x):
+ r"""
+ Args:
+ x (None): A dict with 2 keys, ``padded_targets``, and ``targets``.
+
+ - ``targets`` (list[Tensor]): A list of tensors.
+ Each tensor has the shape of :math:`(T_i)`. Each
+ element is the index of a character.
+ - ``padded_targets`` (Tensor): A tensor of shape :math:`(N)`.
+ Each item is the length of a word.
+
+ Returns:
+ dict: A dict with 2 keys, ``padded_targets``, and ``targets``.
+
+ - ``targets`` (list[Tensor]): A list of tensors.
+ Each tensor has the shape of :math:`(T_i)`. Each
+ element is the index of a character.
+ - ``padded_targets`` (Tensor): A tensor of shape :math:`(N)`.
+ Each item is the length of a word.
+ """
+ return x
+ ```
+
+```{important}
+为了生成 readthedocs 文档,文档的编写需要按照 ReStructrued 文档格式,否则会产生文档渲染错误,在提交 PR 前,最好生成并预览一下文档效果。
+语法规范参考:
+
+- [reStructuredText Primer - Sphinx documentation](https://www.sphinx-doc.org/en/master/usage/restructuredtext/basics.html#)
+- [Example Google Style Python Docstrings ‒ napoleon 0.7 documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html#example-google)
+```
+
+### 注释规范
+
+#### 为什么要写注释
+
+对于一个开源项目,团队合作以及社区之间的合作是必不可少的,因而尤其要重视合理的注释。不写注释的代码,很有可能过几个月自己也难以理解,造成额外的阅读和修改成本。
+
+#### 如何写注释
+
+最需要写注释的是代码中那些技巧性的部分。如果你在下次代码审查的时候必须解释一下,那么你应该现在就给它写注释。对于复杂的操作,应该在其操作开始前写上若干行注释。对于不是一目了然的代码,应在其行尾添加注释。
+—— Google 开源项目风格指南
+
+```python
+# We use a weighted dictionary search to find out where i is in
+# the array. We extrapolate position based on the largest num
+# in the array and the array size and then do binary search to
+# get the exact number.
+if i & (i-1) == 0: # True if i is 0 or a power of 2.
+```
+
+为了提高可读性, 注释应该至少离开代码2个空格.
+另一方面, 绝不要描述代码. 假设阅读代码的人比你更懂Python, 他只是不知道你的代码要做什么.
+—— Google 开源项目风格指南
+
+```python
+# Wrong:
+# Now go through the b array and make sure whenever i occurs
+# the next element is i+1
+
+# Wrong:
+if i & (i-1) == 0: # True if i bitwise and i-1 is 0.
+```
+
+在注释中,可以使用 Markdown 语法,因为开发人员通常熟悉 Markdown 语法,这样可以便于交流理解,如可使用单反引号表示代码和变量(注意不要和 docstring 中的 ReStructured 语法混淆)
+
+```python
+# `_reversed_padding_repeated_twice` is the padding to be passed to
+# `F.pad` if needed (e.g., for non-zero padding types that are
+# implemented as two ops: padding + conv). `F.pad` accepts paddings in
+# reverse order than the dimension.
+self._reversed_padding_repeated_twice = _reverse_repeat_tuple(self.padding, 2)
+```
+
+#### 注释示例
+
+1. 出自 `mmcv/utils/registry.py`,对于较为复杂的逻辑结构,通过注释,明确了优先级关系。
+
+ ```python
+ # self.build_func will be set with the following priority:
+ # 1. build_func
+ # 2. parent.build_func
+ # 3. build_from_cfg
+ if build_func is None:
+ if parent is not None:
+ self.build_func = parent.build_func
+ else:
+ self.build_func = build_from_cfg
+ else:
+ self.build_func = build_func
+ ```
+
+2. 出自 `mmcv/runner/checkpoint.py`,对于 bug 修复中的一些特殊处理,可以附带相关的 issue 链接,帮助其他人了解 bug 背景。
+
+ ```python
+ def _save_ckpt(checkpoint, file):
+ # The 1.6 release of PyTorch switched torch.save to use a new
+ # zipfile-based file format. It will cause RuntimeError when a
+ # checkpoint was saved in high version (PyTorch version>=1.6.0) but
+ # loaded in low version (PyTorch version<1.6.0). More details at
+ # https://github.com/open-mmlab/mmpose/issues/904
+ if digit_version(TORCH_VERSION) >= digit_version('1.6.0'):
+ torch.save(checkpoint, file, _use_new_zipfile_serialization=False)
+ else:
+ torch.save(checkpoint, file)
+ ```
+
+### 类型注解
+
+#### 为什么要写类型注解
+
+类型注解是对函数中变量的类型做限定或提示,为代码的安全性提供保障、增强代码的可读性、避免出现类型相关的错误。
+Python 没有对类型做强制限制,类型注解只起到一个提示作用,通常你的 IDE 会解析这些类型注解,然后在你调用相关代码时对类型做提示。另外也有类型注解检查工具,这些工具会根据类型注解,对代码中可能出现的问题进行检查,减少 bug 的出现。
+需要注意的是,通常我们不需要注释模块中的所有函数:
+
+1. 公共的 API 需要注释
+2. 在代码的安全性,清晰性和灵活性上进行权衡是否注释
+3. 对于容易出现类型相关的错误的代码进行注释
+4. 难以理解的代码请进行注释
+5. 若代码中的类型已经稳定,可以进行注释. 对于一份成熟的代码,多数情况下,即使注释了所有的函数,也不会丧失太多的灵活性.
+
+#### 如何写类型注解
+
+1. 函数 / 方法类型注解,通常不对 self 和 cls 注释。
+
+ ```python
+ from typing import Optional, List, Tuple
+
+ # 全部位于一行
+ def my_method(self, first_var: int) -> int:
+ pass
+
+ # 另起一行
+ def my_method(
+ self, first_var: int,
+ second_var: float) -> Tuple[MyLongType1, MyLongType1, MyLongType1]:
+ pass
+
+ # 单独成行(具体的应用场合与行宽有关,建议结合 yapf 自动化格式使用)
+ def my_method(
+ self, first_var: int, second_var: float
+ ) -> Tuple[MyLongType1, MyLongType1, MyLongType1]:
+ pass
+
+ # 引用尚未被定义的类型
+ class MyClass:
+ def __init__(self,
+ stack: List["MyClass"]) -> None:
+ pass
+ ```
+
+ 注:类型注解中的类型可以是 Python 内置类型,也可以是自定义类,还可以使用 Python 提供的 wrapper 类对类型注解进行装饰,一些常见的注解如下:
+
+ ```python
+ # 数值类型
+ from numbers import Number
+
+ # 可选类型,指参数可以为 None
+ from typing import Optional
+ def foo(var: Optional[int] = None):
+ pass
+
+ # 联合类型,指同时接受多种类型
+ from typing import Union
+ def foo(var: Union[float, str]):
+ pass
+
+ from typing import Sequence # 序列类型
+ from typing import Iterable # 可迭代类型
+ from typing import Any # 任意类型
+ from typing import Callable # 可调用类型
+
+ from typing import List, Dict # 列表和字典的泛型类型
+ from typing import Tuple # 元组的特殊格式
+ # 虽然在 Python 3.9 中,list, tuple 和 dict 本身已支持泛型,但为了支持之前的版本
+ # 我们在进行类型注解时还是需要使用 List, Tuple, Dict 类型
+ # 另外,在对参数类型进行注解时,尽量使用 Sequence & Iterable & Mapping
+ # List, Tuple, Dict 主要用于返回值类型注解
+ # 参见 https://docs.python.org/3/library/typing.html#typing.List
+ ```
+
+2. 变量类型注解,一般用于难以直接推断其类型时
+
+ ```python
+ # Recommend: 带类型注解的赋值
+ a: Foo = SomeUndecoratedFunction()
+ a: List[int]: [1, 2, 3] # List 只支持单一类型泛型,可使用 Union
+ b: Tuple[int, int] = (1, 2) # 长度固定为 2
+ c: Tuple[int, ...] = (1, 2, 3) # 变长
+ d: Dict[str, int] = {'a': 1, 'b': 2}
+
+ # Not Recommend:行尾类型注释
+ # 虽然这种方式被写在了 Google 开源指南中,但这是一种为了支持 Python 2.7 版本
+ # 而补充的注释方式,鉴于我们只支持 Python 3, 为了风格统一,不推荐使用这种方式。
+ a = SomeUndecoratedFunction() # type: Foo
+ a = [1, 2, 3] # type: List[int]
+ b = (1, 2, 3) # type: Tuple[int, ...]
+ c = (1, "2", 3.5) # type: Tuple[int, Text, float]
+ ```
+
+3. 泛型
+
+ 上文中我们知道,typing 中提供了 list 和 dict 的泛型类型,那么我们自己是否可以定义类似的泛型呢?
+
+ ```python
+ from typing import TypeVar, Generic
+
+ KT = TypeVar('KT')
+ VT = TypeVar('VT')
+
+ class Mapping(Generic[KT, VT]):
+ def __init__(self, data: Dict[KT, VT]):
+ self._data = data
+
+ def __getitem__(self, key: KT) -> VT:
+ return self._data[key]
+ ```
+
+ 使用上述方法,我们定义了一个拥有泛型能力的映射类,实际用法如下:
+
+ ```python
+ mapping = Mapping[str, float]({'a': 0.5})
+ value: float = example['a']
+ ```
+
+ 另外,我们也可以利用 TypeVar 在函数签名中指定联动的多个类型:
+
+ ```python
+ from typing import TypeVar, List
+
+ T = TypeVar('T') # Can be anything
+ A = TypeVar('A', str, bytes) # Must be str or bytes
+
+
+ def repeat(x: T, n: int) -> List[T]:
+ """Return a list containing n references to x."""
+ return [x]*n
+
+
+ def longest(x: A, y: A) -> A:
+ """Return the longest of two strings."""
+ return x if len(x) >= len(y) else y
+ ```
+
+更多关于类型注解的写法请参考 [typing](https://docs.python.org/3/library/typing.html)。
+
+#### 类型注解检查工具
+
+[mypy](https://mypy.readthedocs.io/en/stable/) 是一个 Python 静态类型检查工具。根据你的类型注解,mypy 会检查传参、赋值等操作是否符合类型注解,从而避免可能出现的 bug。
+
+例如如下的一个 Python 脚本文件 test.py:
+
+```python
+def foo(var: int) -> float:
+ return float(var)
+
+a: str = foo('2.0')
+b: int = foo('3.0') # type: ignore
+```
+
+运行 mypy test.py 可以得到如下检查结果,分别指出了第 4 行在函数调用和返回值赋值两处类型错误。而第 5 行同样存在两个类型错误,由于使用了 type: ignore 而被忽略了,只有部分特殊情况可能需要此类忽略。
+
+```
+test.py:4: error: Incompatible types in assignment (expression has type "float", variable has type "int")
+test.py:4: error: Argument 1 to "foo" has incompatible type "str"; expected "int"
+Found 2 errors in 1 file (checked 1 source file)
+```
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/community/contributing.md b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/community/contributing.md
new file mode 100644
index 0000000000000000000000000000000000000000..a53dc3cb44a56fae17265a1b0cae79c427d408a5
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/community/contributing.md
@@ -0,0 +1,278 @@
+## 贡献代码
+
+欢迎加入 MMCV 社区,我们致力于打造最前沿的计算机视觉基础库,我们欢迎任何类型的贡献,包括但不限于
+
+**修复错误**
+
+修复代码实现错误的步骤如下:
+
+1. 如果提交的代码改动较大,建议先提交 issue,并正确描述 issue 的现象、原因和复现方式,讨论后确认修复方案。
+2. 修复错误并补充相应的单元测试,提交拉取请求。
+
+**新增功能或组件**
+
+1. 如果新功能或模块涉及较大的代码改动,建议先提交 issue,确认功能的必要性。
+2. 实现新增功能并添单元测试,提交拉取请求。
+
+**文档补充**
+
+修复文档可以直接提交拉取请求
+
+添加文档或将文档翻译成其他语言步骤如下
+
+1. 提交 issue,确认添加文档的必要性。
+2. 添加文档,提交拉取请求。
+
+### 拉取请求工作流
+
+如果你对拉取请求不了解,没关系,接下来的内容将会从零开始,一步一步地指引你如何创建一个拉取请求。如果你想深入了解拉取请求的开发模式,可以参考 github [官方文档](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+#### 1. 复刻仓库
+
+当你第一次提交拉取请求时,先复刻 OpenMMLab 原代码库,点击 GitHub 页面右上角的 **Fork** 按钮,复刻后的代码库将会出现在你的 GitHub 个人主页下。
+
+
+
+将代码克隆到本地
+
+```shell
+git clone git@github.com:{username}/mmcv.git
+```
+
+添加原代码库为上游代码库
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmcv
+```
+
+检查 remote 是否添加成功,在终端输入 `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmcv.git (fetch)
+origin git@github.com:{username}/mmcv.git (push)
+upstream git@github.com:open-mmlab/mmcv (fetch)
+upstream git@github.com:open-mmlab/mmcv (push)
+```
+
+```{note}
+这里对 origin 和 upstream 进行一个简单的介绍,当我们使用 git clone 来克隆代码时,会默认创建一个 origin 的 remote,它指向我们克隆的代码库地址,而 upstream 则是我们自己添加的,用来指向原始代码库地址。当然如果你不喜欢他叫 upstream,也可以自己修改,比如叫 open-mmlab。我们通常向 origin 提交代码(即 fork 下来的远程仓库),然后向 upstream 提交一个 pull request。如果提交的代码和最新的代码发生冲突,再从 upstream 拉取最新的代码,和本地分支解决冲突,再提交到 origin。
+```
+
+#### 2. 配置 pre-commit
+
+在本地开发环境中,我们使用 [pre-commit](https://pre-commit.com/#intro) 来检查代码风格,以确保代码风格的统一。在提交代码,需要先安装 pre-commit(需要在 MMCV 目录下执行):
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+检查 pre-commit 是否配置成功,并安装 `.pre-commit-config.yaml` 中的钩子:
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+
+
+```{note}
+如果你是中国用户,由于网络原因,可能会出现安装失败的情况,这时可以使用国内源
+
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+如果安装过程被中断,可以重复执行 `pre-commit run ...` 继续安装。
+
+如果提交的代码不符合代码风格规范,pre-commit 会发出警告,并自动修复部分错误。
+
+
+
+如果我们想临时绕开 pre-commit 的检查提交一次代码,可以在 `git commit` 时加上 `--no-verify`(需要保证最后推送至远程仓库的代码能够通过 pre-commit 检查)。
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. 创建开发分支
+
+安装完 pre-commit 之后,我们需要基于 master 创建开发分支,建议的分支命名规则为 `username/pr_name`。
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+在后续的开发中,如果本地仓库的 master 分支落后于 upstream 的 master 分支,我们需要先拉取 upstream 的代码进行同步,再执行上面的命令
+
+```shell
+git pull upstream master
+```
+
+#### 4. 提交代码并在本地通过单元测试
+
+- MMCV 引入了 mypy 来做静态类型检查,以增加代码的鲁棒性。因此我们在提交代码时,需要补充 Type Hints。具体规则可以参考[教程](https://zhuanlan.zhihu.com/p/519335398)。
+
+- 提交的代码同样需要通过单元测试
+
+ ```shell
+ # 通过全量单元测试
+ pytest tests
+
+ # 我们需要保证提交的代码能够通过修改模块的单元测试,以 runner 为例
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ 如果你由于缺少依赖无法运行修改模块的单元测试,可以参考[指引-单元测试](#单元测试)
+
+- 如果修改/添加了文档,参考[指引](#文档渲染)确认文档渲染正常。
+
+#### 5. 推送代码到远程
+
+代码通过单元测试和 pre-commit 检查后,将代码推送到远程仓库,如果是第一次推送,可以在 `git push` 后加上 `-u` 参数以关联远程分支
+
+```shell
+git push -u origin {branch_name}
+```
+
+这样下次就可以直接使用 `git push` 命令推送代码了,而无需指定分支和远程仓库。
+
+#### 6. 提交拉取请求(PR)
+
+(1) 在 GitHub 的 Pull request 界面创建拉取请求
+
+
+(2) 根据指引修改 PR 描述,以便于其他开发者更好地理解你的修改
+
+
+
+描述规范详见[拉取请求规范](#拉取请求规范)
+
+
+
+**注意事项**
+
+(a) PR 描述应该包含修改理由、修改内容以及修改后带来的影响,并关联相关 Issue(具体方式见[文档](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) 如果是第一次为 OpenMMLab 做贡献,需要签署 CLA
+
+
+
+(c) 检查提交的 PR 是否通过 CI(集成测试)
+
+
+
+MMCV 会在不同的平台(Linux、Window、Mac),基于不同版本的 Python、PyTorch、CUDA 对提交的代码进行单元测试,以保证代码的正确性,如果有任何一个没有通过,我们可点击上图中的 `Details` 来查看具体的测试信息,以便于我们修改代码。
+
+(3) 如果 PR 通过了 CI,那么就可以等待其他开发者的 review,并根据 reviewer 的意见,修改代码,并重复 [4](#4-提交代码并本地通过单元测试)-[5](#5-推送代码到远程) 步骤,直到 reviewer 同意合入 PR。
+
+
+
+所有 reviewer 同意合入 PR 后,我们会尽快将 PR 合并到主分支。
+
+#### 7. 解决冲突
+
+随着时间的推移,我们的代码库会不断更新,这时候,如果你的 PR 与主分支存在冲突,你需要解决冲突,解决冲突的方式有两种:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+或者
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+如果你非常善于处理冲突,那么可以使用 rebase 的方式来解决冲突,因为这能够保证你的 commit log 的整洁。如果你不太熟悉 `rebase` 的使用,那么可以使用 `merge` 的方式来解决冲突。
+
+### 指引
+
+#### 单元测试
+
+如果你无法正常执行部分模块的单元测试,例如 [video](https://github.com/open-mmlab/mmcv/tree/master/mmcv/video) 模块,可能是你的当前环境没有安装以下依赖
+
+```shell
+# Linux
+sudo apt-get update -y
+sudo apt-get install -y libturbojpeg
+sudo apt-get install -y ffmpeg
+
+# Windows
+conda install ffmpeg
+```
+
+在提交修复代码错误或新增特性的拉取请求时,我们应该尽可能的让单元测试覆盖所有提交的代码,计算单元测试覆盖率的方法如下
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### 文档渲染
+
+在提交修复代码错误或新增特性的拉取请求时,可能会需要修改/新增模块的 docstring。我们需要确认渲染后的文档样式是正确的。
+本地生成渲染后的文档的方法如下
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### 代码风格
+
+#### Python
+
+[PEP8](https://www.python.org/dev/peps/pep-0008/) 作为 OpenMMLab 算法库首选的代码规范,我们使用以下工具检查和格式化代码
+
+- [flake8](https://github.com/PyCQA/flake8): Python 官方发布的代码规范检查工具,是多个检查工具的封装
+- [isort](https://github.com/timothycrosley/isort): 自动调整模块导入顺序的工具
+- [yapf](https://github.com/google/yapf): Google 发布的代码规范检查工具
+- [codespell](https://github.com/codespell-project/codespell): 检查单词拼写是否有误
+- [mdformat](https://github.com/executablebooks/mdformat): 检查 markdown 文件的工具
+- [docformatter](https://github.com/myint/docformatter): 格式化 docstring 的工具
+
+yapf 和 isort 的配置可以在 [setup.cfg](./setup.cfg) 找到
+
+通过配置 [pre-commit hook](https://pre-commit.com/) ,我们可以在提交代码时自动检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`、`markdown files`,
+修复 `end-of-files`、`float-quoted-strings`、`python-encoding-pragma`、`mixed-line-ending`,调整 `requirments.txt` 的包顺序。
+pre-commit 钩子的配置可以在 [.pre-commit-config](./.pre-commit-config.yaml) 找到。
+
+pre-commit 具体的安装使用方式见[拉取请求](#2-配置-pre-commit)。
+
+更具体的规范请参考 [OpenMMLab 代码规范](code_style.md)。
+
+#### C++ and CUDA
+
+C++ 和 CUDA 的代码规范遵从 [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html)
+
+### 拉取请求规范
+
+1. 使用 [pre-commit hook](https://pre-commit.com),尽量减少代码风格相关问题
+
+2. 一个`拉取请求`对应一个短期分支
+
+3. 粒度要细,一个`拉取请求`只做一件事情,避免超大的`拉取请求`
+
+ - Bad:实现 Faster R-CNN
+ - Acceptable:给 Faster R-CNN 添加一个 box head
+ - Good:给 box head 增加一个参数来支持自定义的 conv 层数
+
+4. 每次 Commit 时需要提供清晰且有意义 commit 信息
+
+5. 提供清晰且有意义的`拉取请求`描述
+
+ - 标题写明白任务名称,一般格式:\[Prefix\] Short description of the pull request (Suffix)
+ - prefix: 新增功能 \[Feature\], 修 bug \[Fix\], 文档相关 \[Docs\], 开发中 \[WIP\] (暂时不会被review)
+ - 描述里介绍`拉取请求`的主要修改内容,结果,以及对其他部分的影响, 参考`拉取请求`模板
+ - 关联相关的`议题` (issue) 和其他`拉取请求`
+
+6. 如果引入了其他三方库,或借鉴了三方库的代码,请确认他们的许可证和 mmcv 兼容,并在借鉴的代码上补充 `This code is inspired from http://`
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/community/pr.md b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/community/pr.md
new file mode 100644
index 0000000000000000000000000000000000000000..427fdf9e4965e404970c761676e7edd29e7b2e56
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/community/pr.md
@@ -0,0 +1,3 @@
+## 拉取请求
+
+本文档的内容已迁移到[贡献指南](contributing.md)。
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/compatibility.md b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/compatibility.md
new file mode 100644
index 0000000000000000000000000000000000000000..6bda56092751e4993533008ef0a751e34565e33e
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/compatibility.md
@@ -0,0 +1,176 @@
+### v1.3.18
+
+部分自定义算子对于不同的设备有不同实现,为此添加的大量宏命令与类型检查使得代码变得难以维护。例如:
+
+```c++
+ if (input.device().is_cuda()) {
+#ifdef MMCV_WITH_CUDA
+ CHECK_CUDA_INPUT(input);
+ CHECK_CUDA_INPUT(rois);
+ CHECK_CUDA_INPUT(output);
+ CHECK_CUDA_INPUT(argmax_y);
+ CHECK_CUDA_INPUT(argmax_x);
+
+ roi_align_forward_cuda(input, rois, output, argmax_y, argmax_x,
+ aligned_height, aligned_width, spatial_scale,
+ sampling_ratio, pool_mode, aligned);
+#else
+ AT_ERROR("RoIAlign is not compiled with GPU support");
+#endif
+ } else {
+ CHECK_CPU_INPUT(input);
+ CHECK_CPU_INPUT(rois);
+ CHECK_CPU_INPUT(output);
+ CHECK_CPU_INPUT(argmax_y);
+ CHECK_CPU_INPUT(argmax_x);
+ roi_align_forward_cpu(input, rois, output, argmax_y, argmax_x,
+ aligned_height, aligned_width, spatial_scale,
+ sampling_ratio, pool_mode, aligned);
+ }
+```
+
+为此我们设计了注册与分发的机制以更好的管理这些算子实现。
+
+```c++
+
+void ROIAlignForwardCUDAKernelLauncher(Tensor input, Tensor rois, Tensor output,
+ Tensor argmax_y, Tensor argmax_x,
+ int aligned_height, int aligned_width,
+ float spatial_scale, int sampling_ratio,
+ int pool_mode, bool aligned);
+
+void roi_align_forward_cuda(Tensor input, Tensor rois, Tensor output,
+ Tensor argmax_y, Tensor argmax_x,
+ int aligned_height, int aligned_width,
+ float spatial_scale, int sampling_ratio,
+ int pool_mode, bool aligned) {
+ ROIAlignForwardCUDAKernelLauncher(
+ input, rois, output, argmax_y, argmax_x, aligned_height, aligned_width,
+ spatial_scale, sampling_ratio, pool_mode, aligned);
+}
+
+// 注册算子的cuda实现
+void roi_align_forward_impl(Tensor input, Tensor rois, Tensor output,
+ Tensor argmax_y, Tensor argmax_x,
+ int aligned_height, int aligned_width,
+ float spatial_scale, int sampling_ratio,
+ int pool_mode, bool aligned);
+REGISTER_DEVICE_IMPL(roi_align_forward_impl, CUDA, roi_align_forward_cuda);
+
+// roi_align.cpp
+// 使用dispatcher根据参数中的Tensor device类型对实现进行分发
+void roi_align_forward_impl(Tensor input, Tensor rois, Tensor output,
+ Tensor argmax_y, Tensor argmax_x,
+ int aligned_height, int aligned_width,
+ float spatial_scale, int sampling_ratio,
+ int pool_mode, bool aligned) {
+ DISPATCH_DEVICE_IMPL(roi_align_forward_impl, input, rois, output, argmax_y,
+ argmax_x, aligned_height, aligned_width, spatial_scale,
+ sampling_ratio, pool_mode, aligned);
+}
+
+```
+
+### v1.3.11
+
+为了灵活地支持更多的后端和硬件,例如 `NVIDIA GPUs` 、`AMD GPUs`,我们重构了 `mmcv/ops/csrc` 目录。注意,这次重构不会影响 API 的使用。更多相关信息,请参考 [PR1206](https://github.com/open-mmlab/mmcv/pull/1206)。
+
+原始的目录结构如下所示
+
+```
+.
+├── common_cuda_helper.hpp
+├── ops_cuda_kernel.cuh
+├── pytorch_cpp_helper.hpp
+├── pytorch_cuda_helper.hpp
+├── parrots_cpp_helper.hpp
+├── parrots_cuda_helper.hpp
+├── parrots_cudawarpfunction.cuh
+├── onnxruntime
+│ ├── onnxruntime_register.h
+│ ├── onnxruntime_session_options_config_keys.h
+│ ├── ort_mmcv_utils.h
+│ ├── ...
+│ ├── onnx_ops.h
+│ └── cpu
+│ ├── onnxruntime_register.cpp
+│ ├── ...
+│ └── onnx_ops_impl.cpp
+├── parrots
+│ ├── ...
+│ ├── ops.cpp
+│ ├── ops_cuda.cu
+│ ├── ops_parrots.cpp
+│ └── ops_pytorch.h
+├── pytorch
+│ ├── ...
+│ ├── ops.cpp
+│ ├── ops_cuda.cu
+│ ├── pybind.cpp
+└── tensorrt
+ ├── trt_cuda_helper.cuh
+ ├── trt_plugin_helper.hpp
+ ├── trt_plugin.hpp
+ ├── trt_serialize.hpp
+ ├── ...
+ ├── trt_ops.hpp
+ └── plugins
+ ├── trt_cuda_helper.cu
+ ├── trt_plugin.cpp
+ ├── ...
+ ├── trt_ops.cpp
+ └── trt_ops_kernel.cu
+```
+
+重构之后,它的结构如下所示
+
+```
+.
+├── common
+│ ├── box_iou_rotated_utils.hpp
+│ ├── parrots_cpp_helper.hpp
+│ ├── parrots_cuda_helper.hpp
+│ ├── pytorch_cpp_helper.hpp
+│ ├── pytorch_cuda_helper.hpp
+│ └── cuda
+│ ├── common_cuda_helper.hpp
+│ ├── parrots_cudawarpfunction.cuh
+│ ├── ...
+│ └── ops_cuda_kernel.cuh
+├── onnxruntime
+│ ├── onnxruntime_register.h
+│ ├── onnxruntime_session_options_config_keys.h
+│ ├── ort_mmcv_utils.h
+│ ├── ...
+│ ├── onnx_ops.h
+│ └── cpu
+│ ├── onnxruntime_register.cpp
+│ ├── ...
+│ └── onnx_ops_impl.cpp
+├── parrots
+│ ├── ...
+│ ├── ops.cpp
+│ ├── ops_parrots.cpp
+│ └── ops_pytorch.h
+├── pytorch
+│ ├── info.cpp
+│ ├── pybind.cpp
+│ ├── ...
+│ ├── ops.cpp
+│ └── cuda
+│ ├── ...
+│ └── ops_cuda.cu
+└── tensorrt
+ ├── trt_cuda_helper.cuh
+ ├── trt_plugin_helper.hpp
+ ├── trt_plugin.hpp
+ ├── trt_serialize.hpp
+ ├── ...
+ ├── trt_ops.hpp
+ └── plugins
+ ├── trt_cuda_helper.cu
+ ├── trt_plugin.cpp
+ ├── ...
+ ├── trt_ops.cpp
+ └── trt_ops_kernel.cu
+```
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/conf.py b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/conf.py
new file mode 100644
index 0000000000000000000000000000000000000000..7bfb9c23a726bb917761c725472d307e6d1d865a
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/conf.py
@@ -0,0 +1,217 @@
+#
+# Configuration file for the Sphinx documentation builder.
+#
+# This file does only contain a selection of the most common options. For a
+# full list see the documentation:
+# http://www.sphinx-doc.org/en/master/config
+
+# -- Path setup --------------------------------------------------------------
+
+# If extensions (or modules to document with autodoc) are in another directory,
+# add these directories to sys.path here. If the directory is relative to the
+# documentation root, use os.path.abspath to make it absolute, like shown here.
+#
+import os
+import sys
+
+import pytorch_sphinx_theme
+from sphinx.builders.html import StandaloneHTMLBuilder
+
+sys.path.insert(0, os.path.abspath('../..'))
+
+version_file = '../../mmcv/version.py'
+with open(version_file) as f:
+ exec(compile(f.read(), version_file, 'exec'))
+__version__ = locals()['__version__']
+
+# -- Project information -----------------------------------------------------
+
+project = 'mmcv'
+copyright = '2018-2022, OpenMMLab'
+author = 'MMCV Authors'
+
+# The short X.Y version
+version = __version__
+# The full version, including alpha/beta/rc tags
+release = __version__
+
+# -- General configuration ---------------------------------------------------
+
+# If your documentation needs a minimal Sphinx version, state it here.
+#
+# needs_sphinx = '1.0'
+
+# Add any Sphinx extension module names here, as strings. They can be
+# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
+# ones.
+
+extensions = [
+ 'sphinx.ext.autodoc',
+ 'sphinx.ext.autosummary',
+ 'sphinx.ext.intersphinx',
+ 'sphinx.ext.napoleon',
+ 'sphinx.ext.viewcode',
+ 'sphinx.ext.autosectionlabel',
+ 'sphinx_markdown_tables',
+ 'myst_parser',
+ 'sphinx_copybutton',
+] # yapf: disable
+
+myst_heading_anchors = 4
+
+myst_enable_extensions = ['colon_fence']
+
+# Configuration for intersphinx
+intersphinx_mapping = {
+ 'python': ('https://docs.python.org/3', None),
+ 'numpy': ('https://numpy.org/doc/stable', None),
+ 'torch': ('https://pytorch.org/docs/stable/', None),
+ 'mmengine': ('https://mmengine.readthedocs.io/en/latest', None),
+}
+
+autodoc_mock_imports = ['mmcv._ext', 'mmcv.utils.ext_loader', 'torchvision']
+autosectionlabel_prefix_document = True
+
+# Add any paths that contain templates here, relative to this directory.
+templates_path = ['_templates']
+
+# The suffix(es) of source filenames.
+# You can specify multiple suffix as a list of string:
+#
+source_suffix = {
+ '.rst': 'restructuredtext',
+ '.md': 'markdown',
+}
+
+# The master toctree document.
+master_doc = 'index'
+
+# The language for content autogenerated by Sphinx. Refer to documentation
+# for a list of supported languages.
+#
+# This is also used if you do content translation via gettext catalogs.
+# Usually you set "language" from the command line for these cases.
+language = 'zh_CN'
+
+# List of patterns, relative to source directory, that match files and
+# directories to ignore when looking for source files.
+# This pattern also affects html_static_path and html_extra_path.
+exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
+
+# The name of the Pygments (syntax highlighting) style to use.
+pygments_style = 'sphinx'
+
+# -- Options for HTML output -------------------------------------------------
+
+# The theme to use for HTML and HTML Help pages. See the documentation for
+# a list of builtin themes.
+#
+# html_theme = 'sphinx_rtd_theme'
+html_theme = 'pytorch_sphinx_theme'
+html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
+
+# Theme options are theme-specific and customize the look and feel of a theme
+# further. For a list of options available for each theme, see the
+# documentation.
+#
+html_theme_options = {
+ 'menu': [
+ {
+ 'name': 'GitHub',
+ 'url': 'https://github.com/open-mmlab/mmcv'
+ },
+ ],
+ # Specify the language of shared menu
+ 'menu_lang': 'cn',
+}
+
+# Add any paths that contain custom static files (such as style sheets) here,
+# relative to this directory. They are copied after the builtin static files,
+# so a file named "default.css" will overwrite the builtin "default.css".
+html_static_path = ['_static']
+html_css_files = ['css/readthedocs.css']
+
+# Custom sidebar templates, must be a dictionary that maps document names
+# to template names.
+#
+# The default sidebars (for documents that don't match any pattern) are
+# defined by theme itself. Builtin themes are using these templates by
+# default: ``['localtoc.html', 'relations.html', 'sourcelink.html',
+# 'searchbox.html']``.
+#
+# html_sidebars = {}
+
+# -- Options for HTMLHelp output ---------------------------------------------
+
+# Output file base name for HTML help builder.
+htmlhelp_basename = 'mmcvdoc'
+
+# -- Options for LaTeX output ------------------------------------------------
+
+latex_elements = {
+ # The paper size ('letterpaper' or 'a4paper').
+ #
+ # 'papersize': 'letterpaper',
+
+ # The font size ('10pt', '11pt' or '12pt').
+ #
+ # 'pointsize': '10pt',
+
+ # Additional stuff for the LaTeX preamble.
+ #
+ # 'preamble': '',
+
+ # Latex figure (float) alignment
+ #
+ # 'figure_align': 'htbp',
+}
+
+# Grouping the document tree into LaTeX files. List of tuples
+# (source start file, target name, title,
+# author, documentclass [howto, manual, or own class]).
+latex_documents = [
+ (master_doc, 'mmcv.tex', 'mmcv Documentation', 'MMCV Contributors',
+ 'manual'),
+]
+
+# -- Options for manual page output ------------------------------------------
+
+# One entry per manual page. List of tuples
+# (source start file, name, description, authors, manual section).
+man_pages = [(master_doc, 'mmcv', 'mmcv Documentation', [author], 1)]
+
+# -- Options for Texinfo output ----------------------------------------------
+
+# Grouping the document tree into Texinfo files. List of tuples
+# (source start file, target name, title, author,
+# dir menu entry, description, category)
+texinfo_documents = [
+ (master_doc, 'mmcv', 'mmcv Documentation', author, 'mmcv',
+ 'One line description of project.', 'Miscellaneous'),
+]
+
+# -- Options for Epub output -------------------------------------------------
+
+# Bibliographic Dublin Core info.
+epub_title = project
+
+# The unique identifier of the text. This can be a ISBN number
+# or the project homepage.
+#
+# epub_identifier = ''
+
+# A unique identification for the text.
+#
+# epub_uid = ''
+
+# A list of files that should not be packed into the epub file.
+epub_exclude_files = ['search.html']
+
+# set priority when building html
+StandaloneHTMLBuilder.supported_image_types = [
+ 'image/svg+xml', 'image/gif', 'image/png', 'image/jpeg'
+]
+# -- Extension configuration -------------------------------------------------
+# Ignore >>> when copying code
+copybutton_prompt_text = r'>>> |\.\.\. '
+copybutton_prompt_is_regexp = True
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/docutils.conf b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/docutils.conf
new file mode 100644
index 0000000000000000000000000000000000000000..0c00c84688701117f231fd0c8ec295fb747b7d8f
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/docutils.conf
@@ -0,0 +1,2 @@
+[html writers]
+table_style: colwidths-auto
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/faq.md b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/faq.md
new file mode 100644
index 0000000000000000000000000000000000000000..6cfb100c631b101fa0cff0650105a3cc7d735e7b
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/faq.md
@@ -0,0 +1,91 @@
+## 常见问题
+
+在这里我们列出了用户经常遇到的问题以及对应的解决方法。如果您遇到了其他常见的问题,并且知道可以帮到大家的解决办法,
+欢迎随时丰富这个列表。
+
+### 安装问题
+
+- KeyError: "xxx: 'yyy is not in the zzz registry'"
+
+ 只有模块所在的文件被导入时,注册机制才会被触发,所以您需要在某处导入该文件,更多详情请查看 [KeyError: "MaskRCNN: 'RefineRoIHead is not in the models registry'"](https://github.com/open-mmlab/mmdetection/issues/5974)。
+
+- "No module named 'mmcv.ops'"; "No module named 'mmcv.\_ext'"
+
+ 1. 使用 `pip uninstall mmcv` 卸载您环境中的 mmcv
+ 2. 参考 [installation instruction](https://mmcv.readthedocs.io/en/latest/get_started/installation.html) 或者 [Build MMCV from source](https://mmcv.readthedocs.io/en/latest/get_started/build.html) 安装 mmcv-full
+
+- "invalid device function" 或者 "no kernel image is available for execution"
+
+ 1. 检查 GPU 的 CUDA 计算能力
+ 2. 运行 `python mmdet/utils/collect_env.py` 来检查 PyTorch、torchvision 和 MMCV 是否是针对正确的 GPU 架构构建的,您可能需要去设置 `TORCH_CUDA_ARCH_LIST` 来重新安装 MMCV。兼容性问题可能会出现在使用旧版的 GPUs,如:colab 上的 Tesla K80 (3.7)
+ 3. 检查运行环境是否和 mmcv/mmdet 编译时的环境相同。例如,您可能使用 CUDA 10.0 编译 mmcv,但在 CUDA 9.0 的环境中运行它
+
+- "undefined symbol" 或者 "cannot open xxx.so"
+
+ 1. 如果符号和 CUDA/C++ 相关(例如:libcudart.so 或者 GLIBCXX),请检查 CUDA/GCC 运行时的版本是否和编译 mmcv 的一致
+ 2. 如果符号和 PyTorch 相关(例如:符号包含 caffe、aten 和 TH),请检查 PyTorch 运行时的版本是否和编译 mmcv 的一致
+ 3. 运行 `python mmdet/utils/collect_env.py` 以检查 PyTorch、torchvision 和 MMCV 构建和运行的环境是否相同
+
+- "RuntimeError: CUDA error: invalid configuration argument"
+
+ 这个错误可能是由于您的 GPU 性能不佳造成的。尝试降低 [THREADS_PER_BLOCK](https://github.com/open-mmlab/mmcv/blob/cac22f8cf5a904477e3b5461b1cc36856c2793da/mmcv/ops/csrc/common_cuda_helper.hpp#L10)
+ 的值并重新编译 mmcv。
+
+- "RuntimeError: nms is not compiled with GPU support"
+
+ 这个错误是由于您的 CUDA 环境没有正确安装。
+ 您可以尝试重新安装您的 CUDA 环境,然后删除 mmcv/build 文件夹并重新编译 mmcv。
+
+- "Segmentation fault"
+
+ 1. 检查 GCC 的版本,通常是因为 PyTorch 版本与 GCC 版本不匹配 (例如 GCC \< 4.9 ),我们推荐用户使用 GCC 5.4,我们也不推荐使用 GCC 5.5, 因为有反馈 GCC 5.5 会导致 "segmentation fault" 并且切换到 GCC 5.4 就可以解决问题
+ 2. 检查是否正确安装 CUDA 版本的 PyTorc。输入以下命令并检查是否返回 True
+ ```shell
+ python -c 'import torch; print(torch.cuda.is_available())'
+ ```
+ 3. 如果 `torch` 安装成功,那么检查 MMCV 是否安装成功。输入以下命令,如果没有报错说明 mmcv-full 安装成。
+ ```shell
+ python -c 'import mmcv; import mmcv.ops'
+ ```
+ 4. 如果 MMCV 与 PyTorch 都安装成功了,则可以使用 `ipdb` 设置断点或者使用 `print` 函数,分析是哪一部分的代码导致了 `segmentation fault`
+
+- "libtorch_cuda_cu.so: cannot open shared object file"
+
+ `mmcv-full` 依赖 `libtorch_cuda_cu.so` 文件,但程序运行时没能找到该文件。我们可以检查该文件是否存在 `~/miniconda3/envs/{environment-name}/lib/python3.7/site-packages/torch/lib` 也可以尝试重装 PyTorch。
+
+- "fatal error C1189: #error: -- unsupported Microsoft Visual Studio version!"
+
+ 如果您在 Windows 上编译 mmcv-full 并且 CUDA 的版本是 9.2,您很可能会遇到这个问题 `"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.2\include\crt/host_config.h(133): fatal error C1189: #error: -- unsupported Microsoft Visual Studio version! Only the versions 2012, 2013, 2015 and 2017 are supported!"`,您可以尝试使用低版本的 Microsoft Visual Studio,例如 vs2017。
+
+- "error: member "torch::jit::detail::ModulePolicy::all_slots" may not be initialized"
+
+ 如果您在 Windows 上编译 mmcv-full 并且 PyTorch 的版本是 1.5.0,您很可能会遇到这个问题 `- torch/csrc/jit/api/module.h(474): error: member "torch::jit::detail::ModulePolicy::all_slots" may not be initialized`。解决这个问题的方法是将 `torch/csrc/jit/api/module.h` 文件中所有 `static constexpr bool all_slots = false;` 替换为 `static bool all_slots = false;`。更多细节可以查看 [member "torch::jit::detail::AttributePolicy::all_slots" may not be initialized](https://github.com/pytorch/pytorch/issues/39394)。
+
+- "error: a member with an in-class initializer must be const"
+
+ 如果您在 Windows 上编译 mmcv-full 并且 PyTorch 的版本是 1.6.0,您很可能会遇到这个问题 `"- torch/include\torch/csrc/jit/api/module.h(483): error: a member with an in-class initializer must be const"`. 解决这个问题的方法是将 `torch/include\torch/csrc/jit/api/module.h` 文件中的所有 `CONSTEXPR_EXCEPT_WIN_CUDA ` 替换为 `const`。更多细节可以查看 [Ninja: build stopped: subcommand failed](https://github.com/open-mmlab/mmcv/issues/575)。
+
+- "error: member "torch::jit::ProfileOptionalOp::Kind" may not be initialized"
+
+ 如果您在 Windows 上编译 mmcv-full 并且 PyTorch 的版本是 1.7.0,您很可能会遇到这个问题 `torch/include\torch/csrc/jit/ir/ir.h(1347): error: member "torch::jit::ProfileOptionalOp::Kind" may not be initialized`. 解决这个问题的方法是修改 PyTorch 中的几个文件:
+
+ - 删除 `torch/include\torch/csrc/jit/ir/ir.h` 文件中的 `static constexpr Symbol Kind = ::c10::prim::profile;` 和 `tatic constexpr Symbol Kind = ::c10::prim::profile_optional;`
+ - 将 `torch\include\pybind11\cast.h` 文件中的 `explicit operator type&() { return *(this->value); }` 替换为 `explicit operator type&() { return *((type*)this->value); }`
+ - 将 `torch/include\torch/csrc/jit/api/module.h` 文件中的 所有 `CONSTEXPR_EXCEPT_WIN_CUDA` 替换为 `const`
+
+ 更多细节可以查看 [Ensure default extra_compile_args](https://github.com/pytorch/pytorch/pull/45956)。
+
+- MMCV 和 MMDetection 的兼容性问题;"ConvWS is already registered in conv layer"
+
+ 请参考 [installation instruction](https://mmdetection.readthedocs.io/en/latest/get_started.html#installation) 为您的 MMDetection 版本安装正确版本的 MMCV。
+
+### 使用问题
+
+- "RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one"
+
+ 1. 这个错误是因为有些参数没有参与 loss 的计算,可能是代码中存在多个分支,导致有些分支没有参与 loss 的计算。更多细节见 [Expected to have finished reduction in the prior iteration before starting a new one](https://github.com/pytorch/pytorch/issues/55582)。
+ 2. 你可以设置 DDP 中的 `find_unused_parameters` 为 `True`,或者手动查找哪些参数没有用到。
+
+- "RuntimeError: Trying to backward through the graph a second time"
+
+ 不能同时设置 `GradientCumulativeOptimizerHook` 和 `OptimizerHook`,这会导致 `loss.backward()` 被调用两次,于是程序抛出 `RuntimeError`。我们只需设置其中的一个。更多细节见 [Trying to backward through the graph a second time](https://github.com/open-mmlab/mmcv/issues/1379)。
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/get_started/article.md b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/get_started/article.md
new file mode 100644
index 0000000000000000000000000000000000000000..96768502cedb607d58ea2dc8d17b3dd8b9af20b2
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/get_started/article.md
@@ -0,0 +1,63 @@
+## 解读文章汇总
+
+这篇文章汇总了 [OpenMMLab](https://www.zhihu.com/people/openmmlab) 解读的部分文章(更多文章和视频见 [OpenMMLabCourse](https://github.com/open-mmlab/OpenMMLabCourse)),如果您有推荐的文章(不一定是 OpenMMLab 发布的文章,可以是自己写的文章),非常欢迎提 [Pull Request](http://127.0.0.1:5501/mmcv/docs/zh_cn/_build/html/community/pr.html) 添加到这里。
+
+### MMCV 解读文章
+
+#### 框架解读
+
+- [MMCV 核心组件分析(一):整体概述](https://zhuanlan.zhihu.com/p/336081587)
+- [MMCV 核心组件分析(二):FileHandler](https://zhuanlan.zhihu.com/p/336097883)
+- [MMCV 核心组件分析(三): FileClient](https://zhuanlan.zhihu.com/p/339190576)
+- [MMCV 核心组件分析(四): Config](https://zhuanlan.zhihu.com/p/346203167)
+- [MMCV 核心组件分析(五): Registry](https://zhuanlan.zhihu.com/p/355271993)
+- [MMCV 核心组件分析(六): Hook](https://zhuanlan.zhihu.com/p/355272220)
+- [MMCV 核心组件分析(七): Runner](https://zhuanlan.zhihu.com/p/355272459)
+- [MMCV Hook 食用指南](https://zhuanlan.zhihu.com/p/448600739)
+- [PyTorch & MMCV Dispatcher 机制解析](https://zhuanlan.zhihu.com/p/451671838)
+
+#### 工具解读
+
+- [训练可视化工具哪款是你的菜?MMCV一行代码随你挑](https://zhuanlan.zhihu.com/p/387078211)
+
+#### 安装指南
+
+- [久等了!Windows 平台 MMCV 的预编译包终于来了!](https://zhuanlan.zhihu.com/p/441653536)
+- [Windows 环境从零安装 mmcv-full](https://zhuanlan.zhihu.com/p/434491590)
+
+#### 知乎问答
+
+- [深度学习科研,如何高效进行代码和实验管理?](https://www.zhihu.com/question/269707221/answer/2480772257)
+- [深度学习方面的科研工作中的实验代码有什么规范和写作技巧?如何妥善管理实验数据?](https://www.zhihu.com/question/268193800/answer/2586000037)
+
+### 下游算法库解读文章
+
+- [MMDetection](https://mmdetection.readthedocs.io/zh_CN/latest/article.html)
+
+### PyTorch 解读文章
+
+- [PyTorch1.11 亮点一览:TorchData、functorch、DDP 静态图](https://zhuanlan.zhihu.com/p/486222256)
+- [PyTorch1.12 亮点一览:DataPipe + TorchArrow 新的数据加载与处理范式](https://zhuanlan.zhihu.com/p/537868554)
+- [PyTorch 源码解读之 nn.Module:核心网络模块接口详解](https://zhuanlan.zhihu.com/p/340453841)
+- [PyTorch 源码解读之 torch.autograd:梯度计算详解](https://zhuanlan.zhihu.com/p/321449610)
+- [PyTorch 源码解读之 torch.utils.data:解析数据处理全流程](https://zhuanlan.zhihu.com/p/337850513)
+- [PyTorch 源码解读之 torch.optim:优化算法接口详解](https://zhuanlan.zhihu.com/p/346205754)
+- [PyTorch 源码解读之 DP & DDP:模型并行和分布式训练解析](https://zhuanlan.zhihu.com/p/343951042)
+- [PyTorch 源码解读之 BN & SyncBN:BN 与 多卡同步 BN 详解](https://zhuanlan.zhihu.com/p/337732517)
+- [PyTorch 源码解读之 torch.cuda.amp: 自动混合精度详解](https://zhuanlan.zhihu.com/p/348554267)
+- [PyTorch 源码解读之 cpp_extension:揭秘 C++/CUDA 算子实现和调用全流程](https://zhuanlan.zhihu.com/p/348555597)
+- [PyTorch 源码解读之即时编译篇](https://zhuanlan.zhihu.com/p/361101354)
+- [PyTorch 源码解读之分布式训练了解一下?](https://zhuanlan.zhihu.com/p/361314953)
+- [PyTorch 源码解读之 torch.serialization & torch.hub](https://zhuanlan.zhihu.com/p/364239544)
+
+### 其他
+
+- [困扰我 48 小时的深拷贝,今天终于...](https://zhuanlan.zhihu.com/p/470892209)
+- [拿什么拯救我的 4G 显卡](https://zhuanlan.zhihu.com/p/430123077)
+- [是谁偷偷动了我的 logger](https://zhuanlan.zhihu.com/p/481383590)
+- [三句话,让 logger 言听计从](https://zhuanlan.zhihu.com/p/487524917)
+- [Logging 不为人知的二三事](https://zhuanlan.zhihu.com/p/502610682)
+- [Type Hints 入门教程,让代码更加规范整洁](https://zhuanlan.zhihu.com/p/519335398)
+- [手把手教你如何高效地在 MMCV 中贡献算子](https://zhuanlan.zhihu.com/p/464492627)
+- [OpenMMLab 支持 IPU 训练芯片](https://zhuanlan.zhihu.com/p/517527926)
+- [基于 MMCV 走上开源大佬之路?](https://zhuanlan.zhihu.com/p/391144979)
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/get_started/build.md b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/get_started/build.md
new file mode 100644
index 0000000000000000000000000000000000000000..95f611bc2e0e616f83de448567d404c2e420981a
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/get_started/build.md
@@ -0,0 +1,300 @@
+## 从源码编译 MMCV
+
+### 编译 mmcv
+
+在编译 mmcv 之前,请确保 PyTorch 已经成功安装在环境中,可以参考 [PyTorch 官方安装文档](https://pytorch.org/get-started/locally/#start-locally)。可使用以下命令验证
+
+```bash
+python -c 'import torch;print(torch.__version__)'
+```
+
+:::{note}
+
+- 如果克隆代码仓库的速度过慢,可以使用以下命令克隆(注意:gitee 的 mmcv 不一定和 github 的保持一致,因为每天只同步一次)
+
+```bash
+git clone https://gitee.com/open-mmlab/mmcv.git
+```
+
+- 如果打算使用 `opencv-python-headless` 而不是 `opencv-python`,例如在一个很小的容器环境或者没有图形用户界面的服务器中,你可以先安装 `opencv-python-headless`,这样在安装 mmcv 依赖的过程中会跳过 `opencv-python`。
+
+- 如果编译过程安装依赖库的时间过长,可以[设置 pypi 源](https://mirrors.tuna.tsinghua.edu.cn/help/pypi/)
+
+```bash
+pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
+```
+
+:::
+
+#### 在 Linux 上编译 mmcv
+
+| TODO: 视频教程
+
+1. 克隆代码仓库
+
+ ```bash
+ git clone https://github.com/open-mmlab/mmcv.git
+ cd mmcv
+ ```
+
+2. 安装 `ninja` 和 `psutil` 以加快编译速度
+
+ ```bash
+ pip install -r requirements/optional.txt
+ ```
+
+3. 检查 nvcc 的版本(要求大于等于 9.2,如果没有 GPU,可以跳过)
+
+ ```bash
+ nvcc --version
+ ```
+
+ 上述命令如果输出以下信息,表示 nvcc 的设置没有问题,否则需要设置 CUDA_HOME
+
+ ```
+ nvcc: NVIDIA (R) Cuda compiler driver
+ Copyright (c) 2005-2020 NVIDIA Corporation
+ Built on Mon_Nov_30_19:08:53_PST_2020
+ Cuda compilation tools, release 11.2, V11.2.67
+ Build cuda_11.2.r11.2/compiler.29373293_0
+ ```
+
+ :::{note}
+ 如果想要支持 ROCm,可以参考 [AMD ROCm](https://rocmdocs.amd.com/en/latest/Installation_Guide/Installation-Guide.html) 安装 ROCm。
+ :::
+
+4. 检查 gcc 的版本(要求大于等于**5.4**)
+
+ ```bash
+ gcc --version
+ ```
+
+5. 开始编译(预估耗时 10 分钟)
+
+ ```bash
+ pip install -e . -v
+ ```
+
+6. 验证安装
+
+ ```bash
+ python .dev_scripts/check_installation.py
+ ```
+
+ 如果上述命令没有报错,说明安装成功。如有报错,请查看[问题解决页面](../faq.html)是否已经有解决方案。
+
+ 如果没有找到解决方案,欢迎提 [issue](https://github.com/open-mmlab/mmcv/issues)。
+
+#### 在 macOS 上编译 mmcv
+
+| TODO: 视频教程
+
+```{note}
+如果你使用的是搭载 apple silicon 的 mac 设备,请安装 PyTorch 1.13+ 的版本,否则会遇到 [issues#2218](https://github.com/open-mmlab/mmcv/issues/2218) 中的问题。
+```
+
+1. 克隆代码仓库
+
+ ```bash
+ git clone https://github.com/open-mmlab/mmcv.git
+ cd mmcv
+ ```
+
+2. 安装 `ninja` 和 `psutil` 以加快编译速度
+
+ ```bash
+ pip install -r requirements/optional.txt
+ ```
+
+3. 开始编译
+
+ ```bash
+ pip install -e .
+ ```
+
+4. 验证安装
+
+ ```bash
+ python .dev_scripts/check_installation.py
+ ```
+
+ 如果上述命令没有报错,说明安装成功。如有报错,请查看[问题解决页面](../faq.md)是否已经有解决方案。
+
+ 如果没有找到解决方案,欢迎提 [issue](https://github.com/open-mmlab/mmcv/issues)。
+
+#### 在 Windows 上编译 mmcv
+
+| TODO: 视频教程
+
+在 Windows 上编译 mmcv 比 Linux 复杂,本节将一步步介绍如何在 Windows 上编译 mmcv。
+
+##### 依赖项
+
+请先安装以下的依赖项:
+
+- [Git](https://git-scm.com/download/win):安装期间,请选择 **add git to Path**
+- [Visual Studio Community 2019](https://visualstudio.microsoft.com):用于编译 C++ 和 CUDA 代码
+- [Miniconda](https://docs.conda.io/en/latest/miniconda.html):包管理工具
+- [CUDA 10.2](https://developer.nvidia.com/cuda-10.2-download-archive):如果只需要 CPU 版本可以不安装 CUDA,安装 CUDA 时,可根据需要进行自定义安装。如果已经安装新版本的显卡驱动,建议取消驱动程序的安装
+
+```{note}
+如果不清楚如何安装以上依赖,请参考[Windows 环境从零安装 mmcv](https://zhuanlan.zhihu.com/p/434491590)。
+另外,你需要知道如何在 Windows 上设置变量环境,尤其是 "PATH" 的设置,以下安装过程都会用到。
+```
+
+##### 通用步骤
+
+1. 从 Windows 菜单启动 Anaconda 命令行
+
+ 如 Miniconda 安装程序建议,不要使用原始的 `cmd.exe` 或是 `powershell.exe`。命令行有两个版本,一个基于 PowerShell,一个基于传统的 `cmd.exe`。请注意以下说明都是使用的基于 PowerShell
+
+2. 创建一个新的 Conda 环境
+
+ ```powershell
+ (base) PS C:\Users\xxx> conda create --name mmcv python=3.7
+ (base) PS C:\Users\xxx> conda activate mmcv # 确保做任何操作前先激活环境
+ ```
+
+3. 安装 PyTorch 时,可以根据需要安装支持 CUDA 或不支持 CUDA 的版本
+
+ ```powershell
+ # CUDA version
+ (mmcv) PS C:\Users\xxx> conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
+ # CPU version
+ (mmcv) PS C:\Users\xxx> conda install install pytorch torchvision cpuonly -c pytorch
+ ```
+
+4. 克隆代码仓库
+
+ ```powershell
+ (mmcv) PS C:\Users\xxx> git clone https://github.com/open-mmlab/mmcv.git
+ (mmcv) PS C:\Users\xxx> cd mmcv
+ ```
+
+5. 安装 `ninja` 和 `psutil` 以加快编译速度
+
+ ```powershell
+ (mmcv) PS C:\Users\xxx\mmcv> pip install -r requirements/optional.txt
+ ```
+
+6. 设置 MSVC 编译器
+
+ 设置环境变量。添加 `C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.27.29110\bin\Hostx86\x64` 到 `PATH`,则 `cl.exe` 可以在命令行中运行,如下所示。
+
+ ```powershell
+ (mmcv) PS C:\Users\xxx\mmcv> cl
+ Microsoft (R) C/C++ Optimizing Compiler Version 19.27.29111 for x64
+ Copyright (C) Microsoft Corporation. All rights reserved.
+
+ usage: cl [ option... ] filename... [ / link linkoption... ]
+ ```
+
+ 为了兼容性,我们使用 x86-hosted 以及 x64-targeted 版本,即路径中的 `Hostx86\x64` 。
+
+ 因为 PyTorch 将解析 `cl.exe` 的输出以检查其版本,只有 utf-8 将会被识别,你可能需要将系统语言更改为英语。控制面板 -> 地区-> 管理-> 非 Unicode 来进行语言转换。
+
+##### 编译与安装 mmcv
+
+mmcv 有两个版本:
+
+- 只包含 CPU 算子的版本
+
+ 编译 CPU 算子,但只有 x86 将会被编译,并且编译版本只能在 CPU only 情况下运行
+
+- 既包含 CPU 算子,又包含 CUDA 算子的版本
+
+ 同时编译 CPU 和 CUDA 算子,`ops` 模块的 x86 与 CUDA 的代码都可以被编译。同时编译的版本可以在 CUDA 上调用 GPU
+
+###### CPU 版本
+
+编译安装
+
+```powershell
+(mmcv) PS C:\Users\xxx\mmcv> python setup.py build_ext # 如果成功, cl 将被启动用于编译算子
+(mmcv) PS C:\Users\xxx\mmcv> python setup.py develop # 安装
+```
+
+###### GPU 版本
+
+1. 检查 `CUDA_PATH` 或者 `CUDA_HOME` 环境变量已经存在在 `envs` 之中
+
+ ```powershell
+ (mmcv) PS C:\Users\xxx\mmcv> ls env:
+
+ Name Value
+ ---- -----
+ CUDA_PATH C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2
+ CUDA_PATH_V10_1 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1
+ CUDA_PATH_V10_2 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2
+ ```
+
+ 如果没有,你可以按照下面的步骤设置
+
+ ```powershell
+ (mmcv) PS C:\Users\xxx\mmcv> $env:CUDA_HOME = "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2"
+ # 或者
+ (mmcv) PS C:\Users\xxx\mmcv> $env:CUDA_HOME = $env:CUDA_PATH_V10_2 # CUDA_PATH_V10_2 已经在环境变量中
+ ```
+
+2. 设置 CUDA 的目标架构
+
+ ```powershell
+ # 这里需要改成你的显卡对应的目标架构
+ (mmcv) PS C:\Users\xxx\mmcv> $env:TORCH_CUDA_ARCH_LIST="7.5"
+ ```
+
+ :::{note}
+ 可以点击 [cuda-gpus](https://developer.nvidia.com/cuda-gpus) 查看 GPU 的计算能力,也可以通过 CUDA 目录下的 deviceQuery.exe 工具查看
+
+ ```powershell
+ (mmcv) PS C:\Users\xxx\mmcv> &"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\extras\demo_suite\deviceQuery.exe"
+ Device 0: "NVIDIA GeForce GTX 1660 SUPER"
+ CUDA Driver Version / Runtime Version 11.7 / 11.1
+ CUDA Capability Major/Minor version number: 7.5
+ ```
+
+ 上面的 7.5 表示目标架构。注意:需把上面命令的 v10.2 换成你的 CUDA 版本。
+ :::
+
+3. 编译安装
+
+ ```powershell
+ (mmcv) PS C:\Users\xxx\mmcv> python setup.py build_ext # 如果成功, cl 将被启动用于编译算子
+ (mmcv) PS C:\Users\xxx\mmcv> python setup.py develop # 安装
+ ```
+
+ ```{note}
+ 如果你的 PyTorch 版本是 1.6.0,你可能会遇到一些 [issue](https://github.com/pytorch/pytorch/issues/42467) 提到的错误,你可以参考这个 [pull request](https://github.com/pytorch/pytorch/pull/43380/files) 修改本地环境的 PyTorch 源代码
+ ```
+
+##### 验证安装
+
+```powershell
+(mmcv) PS C:\Users\xxx\mmcv> python .dev_scripts/check_installation.py
+```
+
+如果上述命令没有报错,说明安装成功。如有报错,请查看[问题解决页面](../faq.md)是否已经有解决方案。
+如果没有找到解决方案,欢迎提 [issue](https://github.com/open-mmlab/mmcv/issues)。
+
+### 编译 mmcv-lite
+
+如果你需要使用和 PyTorch 相关的模块,请确保 PyTorch 已经成功安装在环境中,可以参考 [PyTorch 官方安装文档](https://pytorch.org/get-started/locally/#start-locally)。
+
+1. 克隆代码仓库
+
+ ```bash
+ git clone https://github.com/open-mmlab/mmcv.git
+ cd mmcv
+ ```
+
+2. 开始编译
+
+ ```bash
+ MMCV_WITH_OPS=0 pip install -e . -v
+ ```
+
+3. 验证安装
+
+ ```bash
+ python -c 'import mmcv;print(mmcv.__version__)'
+ ```
diff --git a/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/get_started/installation.md b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/get_started/installation.md
new file mode 100644
index 0000000000000000000000000000000000000000..54cdbd9f3ab9c2694e78013f5b3a5841730c54a5
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/docs/zh_cn/get_started/installation.md
@@ -0,0 +1,369 @@
+## 安装 MMCV
+
+MMCV 有两个版本:
+
+- **mmcv**: 完整版,包含所有的特性以及丰富的开箱即用的 CPU 和 CUDA 算子。注意,完整版本可能需要更长时间来编译。
+- **mmcv-lite**: 精简版,不包含 CPU 和 CUDA 算子但包含其余所有特性和功能,类似 MMCV 1.0 之前的版本。如果你不需要使用算子的话,精简版可以作为一个考虑选项。
+
+```{warning}
+请不要在同一个环境中安装两个版本,否则可能会遇到类似 `ModuleNotFound` 的错误。在安装一个版本之前,需要先卸载另一个。`如果 CUDA 可用,强烈推荐安装 mmcv`。
+```
+
+### 安装 mmcv
+
+在安装 mmcv 之前,请确保 PyTorch 已经成功安装在环境中,可以参考 [PyTorch 官方安装文档](https://pytorch.org/get-started/locally/#start-locally)。可使用以下命令验证
+
+```bash
+python -c 'import torch;print(torch.__version__)'
+```
+
+如果输出版本信息,则表示 PyTorch 已安装。
+
+#### 使用 mim 安装(推荐)
+
+[mim](https://github.com/open-mmlab/mim) 是 OpenMMLab 项目的包管理工具,使用它可以很方便地安装 mmcv。
+
+```bash
+pip install -U openmim
+mim install "mmcv>=2.0.0rc1"
+```
+
+如果发现上述的安装命令没有使用预编译包(以 `.whl` 结尾)而是使用源码包(以 `.tar.gz` 结尾)安装,则有可能是我们没有提供和当前环境的 PyTorch 版本、CUDA 版本相匹配的 mmcv 预编译包,此时,你可以[源码安装 mmcv](build.md)。
+
+
+使用预编译包的安装日志
+
+Looking in links: https://download.openmmlab.com/mmcv/dist/cu102/torch1.8.0/index.html
+Collecting mmcv
+Downloading https://download.openmmlab.com/mmcv/dist/cu102/torch1.8.0/mmcv-2.0.0rc3-cp38-cp38-manylinux1_x86_64.whl
+
+
+
+
+使用源码包的安装日志
+
+Looking in links: https://download.openmmlab.com/mmcv/dist/cu102/torch1.8.0/index.html
+Collecting mmcv==2.0.0rc3
+Downloading mmcv-2.0.0rc3.tar.gz
+
+
+
+如需安装指定版本的 mmcv,例如安装 2.0.0rc3 版本的 mmcv,可使用以下命令
+
+```bash
+mim install mmcv==2.0.0rc3
+```
+
+:::{note}
+如果你打算使用 `opencv-python-headless` 而不是 `opencv-python`,例如在一个很小的容器环境或者没有图形用户界面的服务器中,你可以先安装 `opencv-python-headless`,这样在安装 mmcv 依赖的过程中会跳过 `opencv-python`。
+
+另外,如果安装依赖库的时间过长,可以指定 pypi 源
+
+```bash
+mim install "mmcv>=2.0.0rc1" -i https://pypi.tuna.tsinghua.edu.cn/simple
+```
+
+:::
+
+安装完成后可以运行 [check_installation.py](https://github.com/open-mmlab/mmcv/blob/2.x/.dev_scripts/check_installation.py) 脚本检查 mmcv 是否安装成功。
+
+#### 使用 pip 安装
+
+使用以下命令查看 CUDA 和 PyTorch 的版本
+
+```bash
+python -c 'import torch;print(torch.__version__);print(torch.version.cuda)'
+```
+
+根据系统的类型、CUDA 版本、PyTorch 版本以及 MMCV 版本选择相应的安装命令
+
+
+
+
+
 +
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/mmcv.git
+```
+
+After that, you should ddd official repository as the upstream repository
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmcv
+```
+
+Check whether remote repository has been added successfully by `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmcv.git (fetch)
+origin git@github.com:{username}/mmcv.git (push)
+upstream git@github.com:open-mmlab/mmcv (fetch)
+upstream git@github.com:open-mmlab/mmcv (push)
+```
+
+> Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+
+#### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of OpenMMLab. **Note**: The following code should be executed under the MMCV directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/mmcv.git
+```
+
+After that, you should ddd official repository as the upstream repository
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmcv
+```
+
+Check whether remote repository has been added successfully by `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmcv.git (fetch)
+origin git@github.com:{username}/mmcv.git (push)
+upstream git@github.com:open-mmlab/mmcv (fetch)
+upstream git@github.com:open-mmlab/mmcv (push)
+```
+
+> Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+
+#### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of OpenMMLab. **Note**: The following code should be executed under the MMCV directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+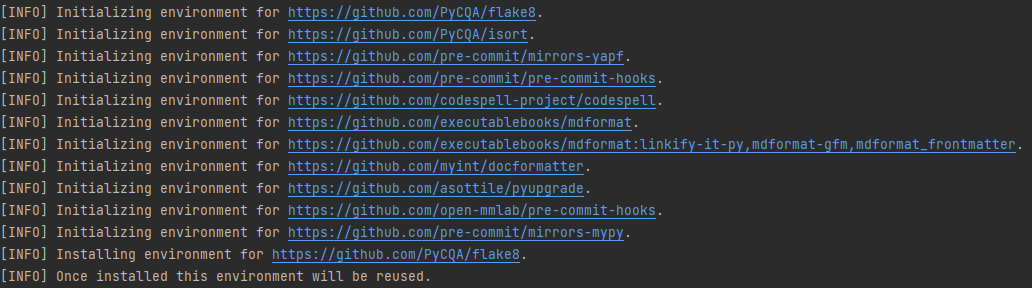 +
+
+
+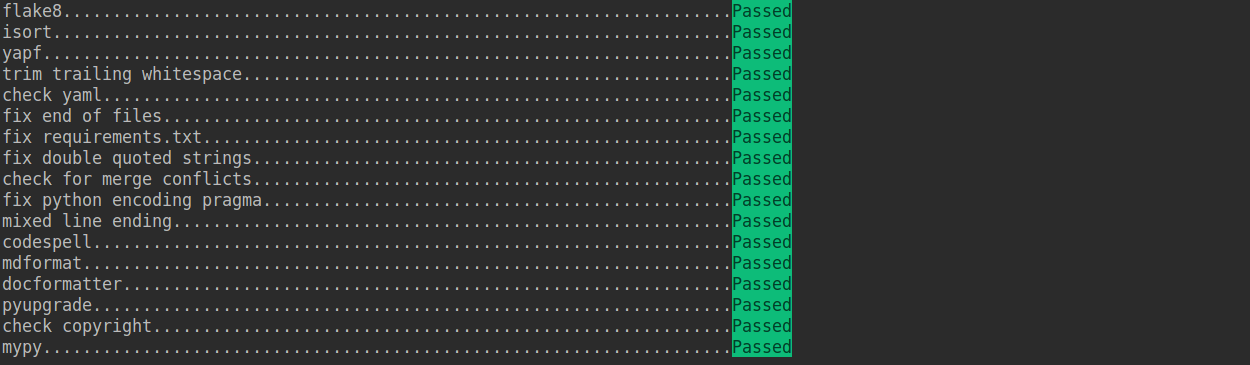 +
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+
+
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+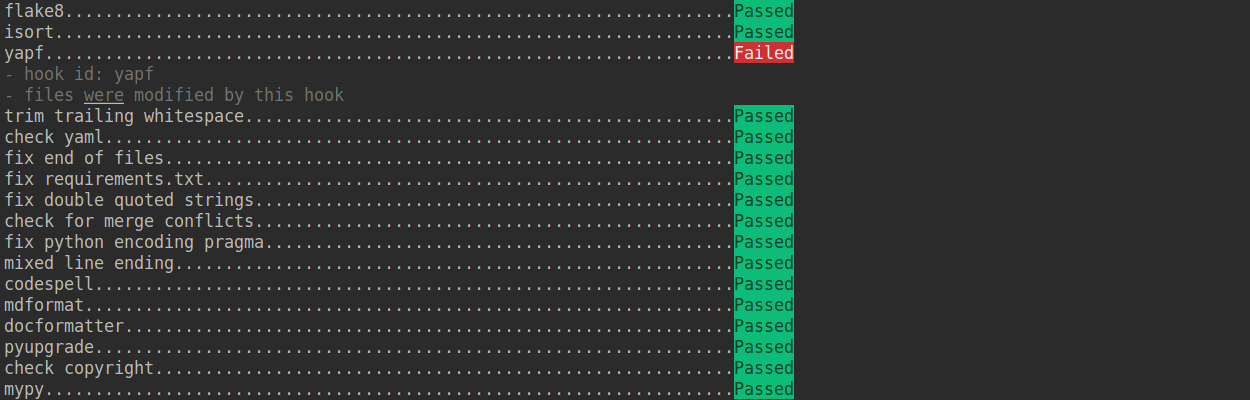 +
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**).
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream master
+```
+
+#### 4. Commit the code and pass the unit test
+
+- MMCV introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of runner
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+#### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
+
+#### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+
+
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**).
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream master
+```
+
+#### 4. Commit the code and pass the unit test
+
+- MMCV introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of runner
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+#### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
+
+#### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+ +
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
+
+
+
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
+
+ +
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)
+
+(b) If it is your first contribution, please sign the CLA
+
+
+
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)
+
+(b) If it is your first contribution, please sign the CLA
+
+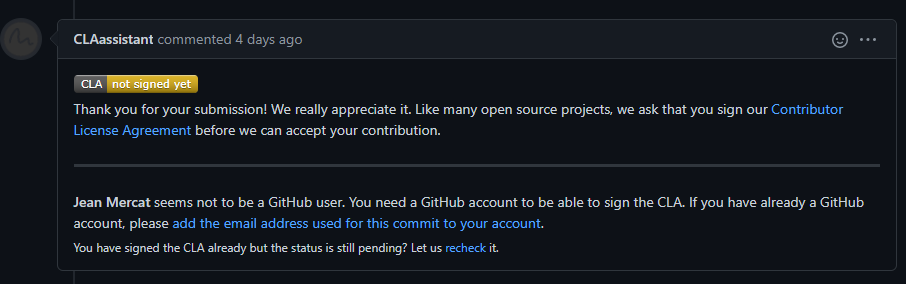 +
+(c) Check whether the Pull Request pass through the CI
+
+
+
+(c) Check whether the Pull Request pass through the CI
+
+ +
+MMCV will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+
+
+MMCV will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+ +
+#### 7. Resolve conflicts
+
+If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
+
+### Guidance
+
+#### Unit test
+
+If you cannot run the unit test of some modules for lacking of some dependencies, such as [video](https://github.com/open-mmlab/mmcv/tree/master/mmcv/video) module, you can try to install the following dependencies:
+
+```shell
+# Linux
+sudo apt-get update -y
+sudo apt-get install -y libturbojpeg
+sudo apt-get install -y ffmpeg
+
+# Windows
+conda install ffmpeg
+```
+
+We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Code style
+
+#### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](./setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `float-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](./.pre-commit-config.yaml).
+
+#### C++ and CUDA
+
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
+
+### PR Specs
+
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
+
+2. One short-time branch should be matched with only one PR
+
+3. Accomplish a detailed change in one PR. Avoid large PR
+
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
+
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/cv/distiller/CWD/pytorch/mmcv/CONTRIBUTING_zh-CN.md b/cv/distiller/CWD/pytorch/mmcv/CONTRIBUTING_zh-CN.md
new file mode 100644
index 0000000000000000000000000000000000000000..52cc1ab5b2d399557647604018c494e4f93a1d24
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/CONTRIBUTING_zh-CN.md
@@ -0,0 +1,274 @@
+## 贡献代码
+
+欢迎加入 MMCV 社区,我们致力于打造最前沿的计算机视觉基础库,我们欢迎任何类型的贡献,包括但不限于
+
+**修复错误**
+
+修复代码实现错误的步骤如下:
+
+1. 如果提交的代码改动较大,建议先提交 issue,并正确描述 issue 的现象、原因和复现方式,讨论后确认修复方案。
+2. 修复错误并补充相应的单元测试,提交拉取请求。
+
+**新增功能或组件**
+
+1. 如果新功能或模块涉及较大的代码改动,建议先提交 issue,确认功能的必要性。
+2. 实现新增功能并添单元测试,提交拉取请求。
+
+**文档补充**
+
+修复文档可以直接提交拉取请求
+
+添加文档或将文档翻译成其他语言步骤如下
+
+1. 提交 issue,确认添加文档的必要性。
+2. 添加文档,提交拉取请求。
+
+### 拉取请求工作流
+
+如果你对拉取请求不了解,没关系,接下来的内容将会从零开始,一步一步地指引你如何创建一个拉取请求。如果你想深入了解拉取请求的开发模式,可以参考 github [官方文档](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+#### 1. 复刻仓库
+
+当你第一次提交拉取请求时,先复刻 OpenMMLab 原代码库,点击 GitHub 页面右上角的 **Fork** 按钮,复刻后的代码库将会出现在你的 GitHub 个人主页下。
+
+
+
+#### 7. Resolve conflicts
+
+If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
+
+### Guidance
+
+#### Unit test
+
+If you cannot run the unit test of some modules for lacking of some dependencies, such as [video](https://github.com/open-mmlab/mmcv/tree/master/mmcv/video) module, you can try to install the following dependencies:
+
+```shell
+# Linux
+sudo apt-get update -y
+sudo apt-get install -y libturbojpeg
+sudo apt-get install -y ffmpeg
+
+# Windows
+conda install ffmpeg
+```
+
+We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Code style
+
+#### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](./setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `float-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](./.pre-commit-config.yaml).
+
+#### C++ and CUDA
+
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
+
+### PR Specs
+
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
+
+2. One short-time branch should be matched with only one PR
+
+3. Accomplish a detailed change in one PR. Avoid large PR
+
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
+
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/cv/distiller/CWD/pytorch/mmcv/CONTRIBUTING_zh-CN.md b/cv/distiller/CWD/pytorch/mmcv/CONTRIBUTING_zh-CN.md
new file mode 100644
index 0000000000000000000000000000000000000000..52cc1ab5b2d399557647604018c494e4f93a1d24
--- /dev/null
+++ b/cv/distiller/CWD/pytorch/mmcv/CONTRIBUTING_zh-CN.md
@@ -0,0 +1,274 @@
+## 贡献代码
+
+欢迎加入 MMCV 社区,我们致力于打造最前沿的计算机视觉基础库,我们欢迎任何类型的贡献,包括但不限于
+
+**修复错误**
+
+修复代码实现错误的步骤如下:
+
+1. 如果提交的代码改动较大,建议先提交 issue,并正确描述 issue 的现象、原因和复现方式,讨论后确认修复方案。
+2. 修复错误并补充相应的单元测试,提交拉取请求。
+
+**新增功能或组件**
+
+1. 如果新功能或模块涉及较大的代码改动,建议先提交 issue,确认功能的必要性。
+2. 实现新增功能并添单元测试,提交拉取请求。
+
+**文档补充**
+
+修复文档可以直接提交拉取请求
+
+添加文档或将文档翻译成其他语言步骤如下
+
+1. 提交 issue,确认添加文档的必要性。
+2. 添加文档,提交拉取请求。
+
+### 拉取请求工作流
+
+如果你对拉取请求不了解,没关系,接下来的内容将会从零开始,一步一步地指引你如何创建一个拉取请求。如果你想深入了解拉取请求的开发模式,可以参考 github [官方文档](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+#### 1. 复刻仓库
+
+当你第一次提交拉取请求时,先复刻 OpenMMLab 原代码库,点击 GitHub 页面右上角的 **Fork** 按钮,复刻后的代码库将会出现在你的 GitHub 个人主页下。
+
+

 +
+ +
+